Data Cleaning Essentials focus on preparing raw data for analysis by identifying and fixing errors, missing values, and inconsistencies.
Clean data improves accuracy, reliability, and the overall quality of insights in the data science process.
Handling Duplicates
Duplicate data is a major issue in datasets generated through CRM systems, log collections, form submissions, and multi-platform data integration pipelines.
Duplicates artificially inflate counts, confuse joins, and result in biased insights—particularly in customer analytics, fraud detection, and recommendation systems.
A. Identifying Exact and Near-Duplicates
Exact duplicates share completely identical values in all fields.
Near-duplicates differ slightly in spelling or formatting but refer to the same real-world entity (e.g., “Samir Gupta” vs. “Sameer Gupta”).
Why Detection Matters
1. Duplicate customers lead to incorrect lifetime value calculations.
2. Duplicate transactions inflate revenue or usage counts.
3. Duplicate logs distort behavioral analytics.
How Duplicates are Detected
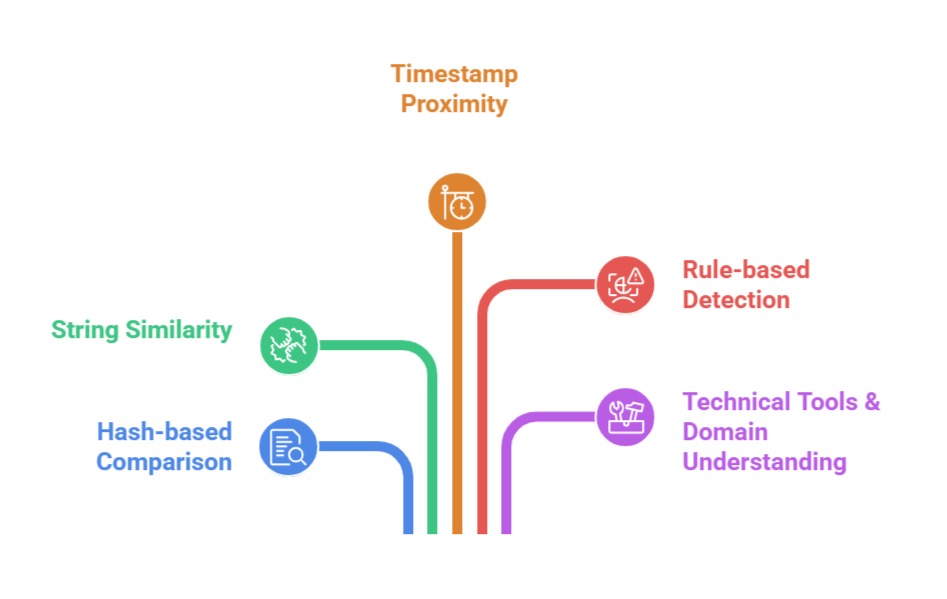
B. Deduplication Rules Based on Priority Fields
Not all fields contribute equally to identifying a unique entity.
For customers, email might be the most reliable. For shipments, tracking number might be most important. For bank transactions, timestamp + amount + account ID may define uniqueness.
Why Rules Matter
Without clear rules, you may accidentally delete valid entries or merge records incorrectly.
Examples of Deduplication Keys
Customer records: email, phone number
Orders: order ID, invoice ID
Medical records: patient ID, visit ID
Web logs: IP + timestamp + session ID
Defined keys ensure deduplication is safe and accurate.
C. Merging or Removing Duplicate Entries
Once duplicates are identified, analysts must decide whether to remove or merge them.
When to Remove
1. Duplicate log entries
2. Repeated survey submissions
3. System-generated redundant rows
When to Merge
1. Customer appears with small spelling differences
2. Multiple entries contain partial information
3. Sensor readings split across duplicate timestamps
4. Merged records often provide richer and more accurate information.
Fixing Outliers and Anomalies
Outliers appear in nearly every dataset—financial records, website logs, sensor data, medical statistics, and more.
They can represent true rare events or simply errors. Properly identifying and treating outliers ensures your analysis is balanced, unbiased, and meaningful.
A. Detecting Outliers Using Statistical Methods
Statistical detection helps determine whether values lie outside normal ranges.
Methods include
Z-Score Method: Identifies values far from the mean (|z| > 3)
IQR Method: Values below Q1−1.5×IQR or above Q3+1.5×IQR
Box plots & scatter plots: Visual inspection for anomalies
Why Use Statistics: Outliers can distort averages, stretch model decision boundaries, and create instability in training. Statistical detection provides objective thresholds.
B. Understanding Context Before Removal
Not all outliers are errors.
Examples
1. High-value purchases in e-commerce
2. Rare medical abnormalities
3. Sudden spikes in server usage during a product launch
Why Context Matters
Removing real rare events destroys useful patterns and biases your model. Domain experts should confirm whether outliers represent errors or genuine behavior.
Best Practice: Always analyze outliers with domain logic and stakeholder input before deciding what action to take.
C. Treating Outliers Using Transformations or Capping
Outliers can be handled without deletion:
Common Techniques
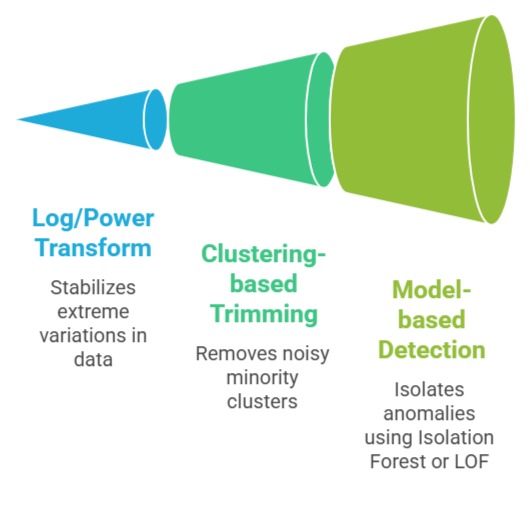
Why These Techniques Work
Winsorization: Cap extreme values to percentile thresholds
They preserve data while minimizing distortion. This is especially important when modeling distributions or using distance-based algorithms like kNN.
Validating Data Consistency
Consistency ensures that all data follows logical rules and matches across related systems.
In multi-database environments—ERP, CRM, HRM—consistency issues become significant due to syncing errors, partial updates, or incorrect logic.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.