Key challenges in generative modeling arise from both training instability and difficulties in measuring model quality. Mode collapse occurs when a model generates limited or repetitive outputs instead of capturing the full diversity of the data distribution.
Posterior collapse happens when latent variables are ignored during training, reducing the effectiveness of probabilistic models. In addition, evaluating generative models is challenging because traditional accuracy metrics are often insufficient, requiring specialized evaluation techniques.
Mode Collapse in GANs
Mode collapse happens when a GAN's generator gets stuck producing variations of just a few data samples, completely ignoring the full diversity of the training set—like generating only dalmatian patterns from a varied animal dataset.
This training pathology disrupts the adversarial balance and demands specific diagnostics and remedies.
In GANs, the generator and discriminator compete: the generator creates fakes, discriminator exposes them. Collapse occurs when the generator finds a narrow set of "easy wins" that consistently fool the discriminator.
Common Causes and Visual Symptoms
Multiple triggers lead to this failure mode.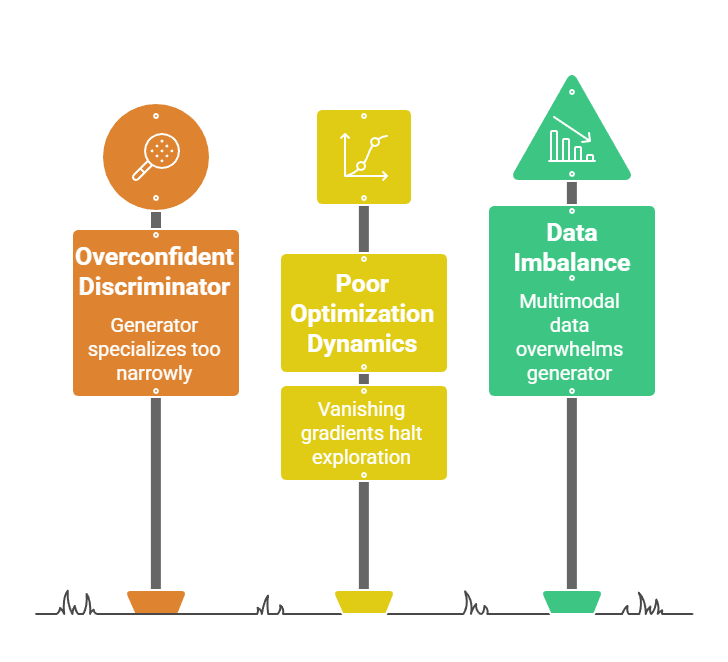
Tell-Tale Signs
1. Identical outputs across random seeds.
2. Generator loss plummets while diversity vanishes.
3. Detection Code Snippet (Python with PyTorch):
import torch
from torchvision.utils import make_grid
def check_mode_collapse(generated_samples):
unique_imgs = len(set([tuple(img.flatten().numpy()) for img in generated_samples]))
diversity_score = unique_imgs / len(generated_samples)
return diversity_score < 0.1 # Alert if <10% uniqueProven Mitigation Techniques
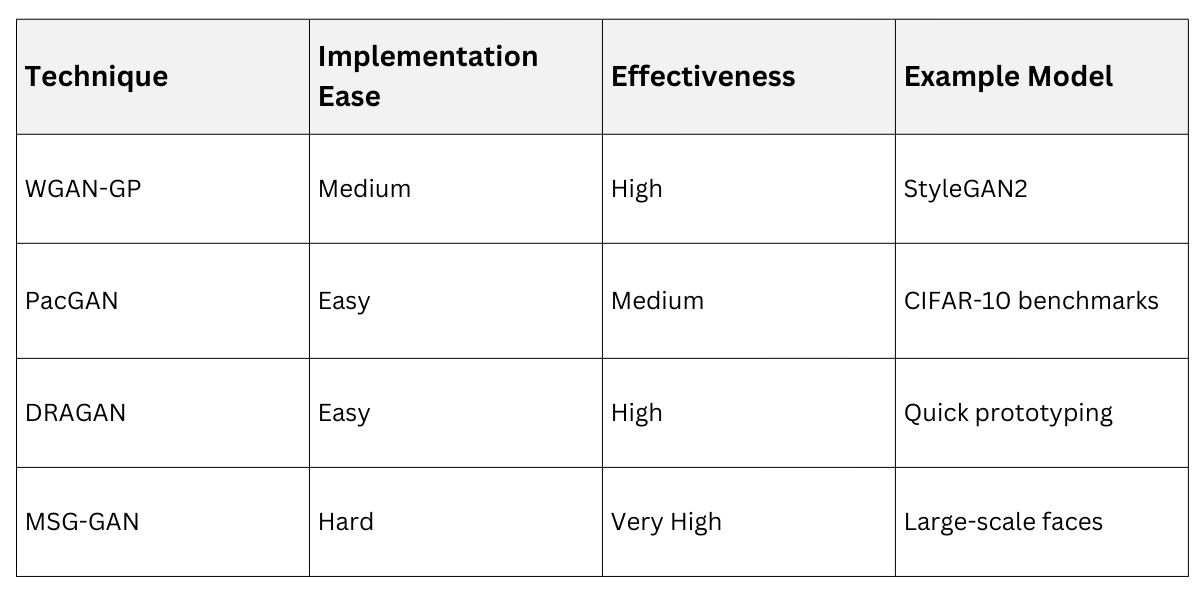
Implement these strategies progressively.
1. Gradient penalty (WGAN-GP): Penalize discriminator deviations from 1-Lipschitz constraint.
2. Mini-batch discrimination: Add statistics layer to discriminator for better mode coverage.
3. Unrolled GANs: Train discriminator multiple steps per generator update.
4. Multiple generators: Competition prevents single-point failures.
Real Example: BigGAN uses truncation tricks alongside these to generate diverse ImageNet classes without collapse.
Posterior Collapse in VAEs
Posterior collapse in VAEs occurs when the latent space becomes useless—the encoder outputs identical distributions for all inputs, and the decoder reconstructs without latent guidance, like a photocopier ignoring learned features.
This erodes VAEs' strength in structured latent representations for controllable generation.
VAEs train by optimizing reconstruction loss plus KL divergence between learned posterior and standard prior. Collapse happens when KL terms dominate early, making latents match the prior exactly.
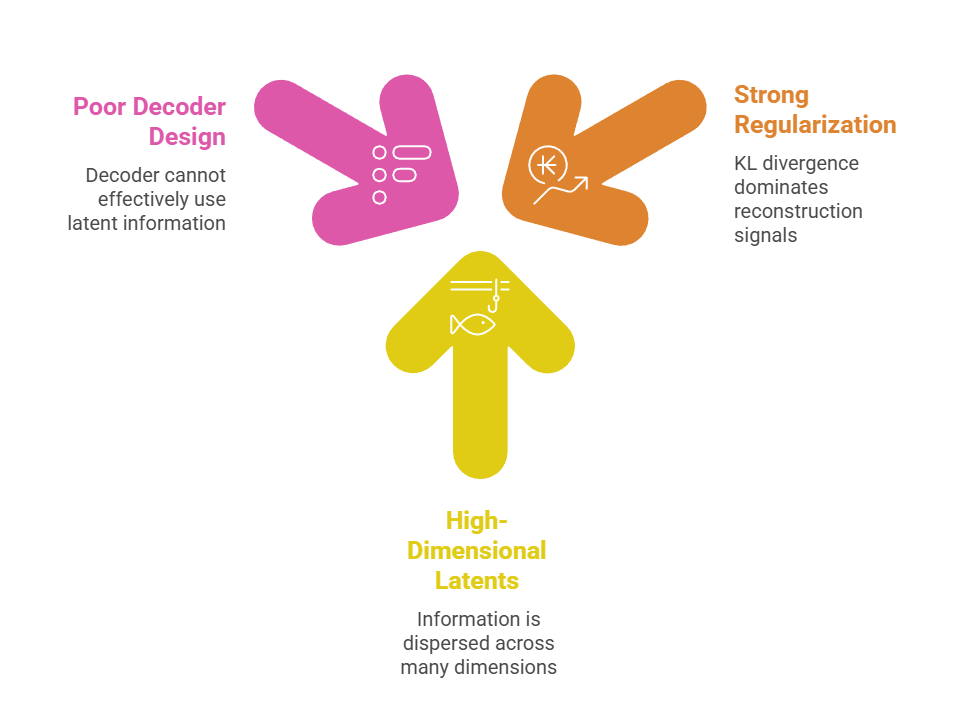
Root Causes and Diagnostics
Key contributors include mismatched model capacities.
Diagnostic Metrics
1. Active units: Fraction of latents with KL > threshold (aim >80%).
2. Latent variance: Collapse if near-zero across batch.
Monitoring Code
def monitor_active_units(kl_divs, threshold=0.01):
active = (kl_divs > threshold).float().mean().item()
print(f"Active units: {active:.2%}")
return active > 0.8Modern Solutions
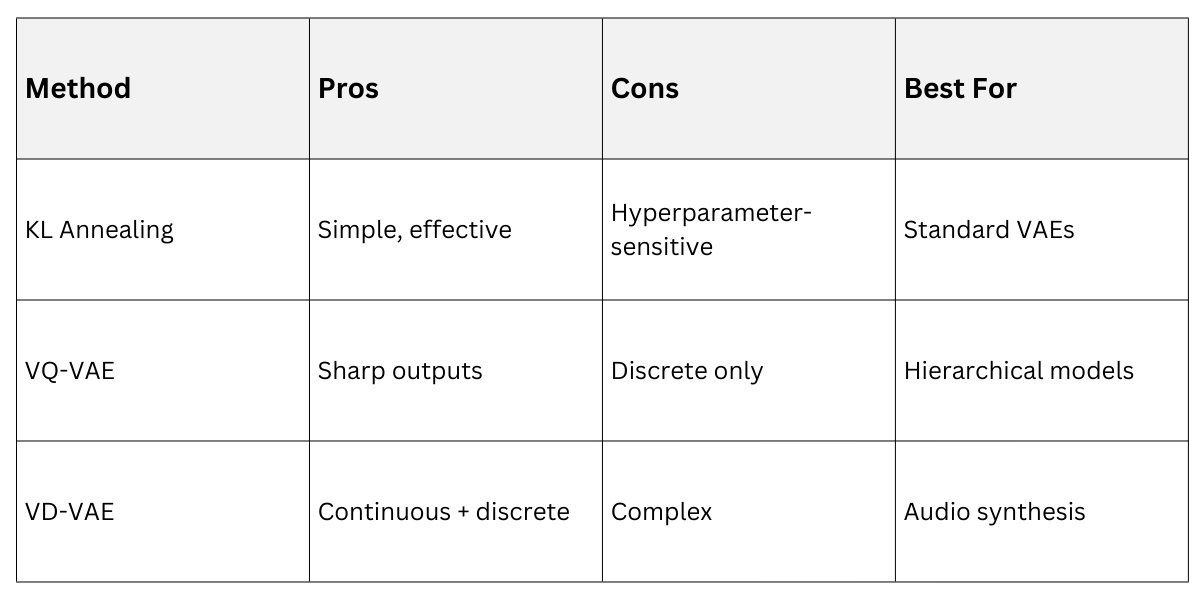
2025 best practices emphasize gradual training.
1. KL annealing: Ramp KL weight from 0 to 1 over epochs.
2. Free bits: Limit KL per dimension to preserve info.
3. VQ-VAE: Vector quantization forces discrete latent usage.
4. β-VAE with cyclical annealing: Oscillates β for exploration.
Case Study: VQ-VAE-2 on ImageNet avoids collapse entirely, enabling crisp generations used in DALL-E.
 Evaluation Metrics: Beyond Visual Inspection
Evaluation Metrics: Beyond Visual Inspection
Generative model evaluation lacks ground truth, so metrics like FID, Inception Score (IS), and human evaluation provide quantitative proxies—but each has blind spots requiring careful interpretation.
Reliable metrics guide architecture choices and hyperparameter tuning in practice.
Core Challenge: Metrics must balance sample quality (realism), diversity (mode coverage), and semantic alignment.
Primary Automated Metrics
Here's the toolkit with practical thresholds.
.png)
FID Computation Code (using torch-fid library)
# pip install pytorch-fid
from pytorch_fid import fid_score
fid_value = fid_score.calculate_fid_given_paths(real_path, fake_path)
print(f"FID: {fid_value:.2f}") # Target < 10 for strong models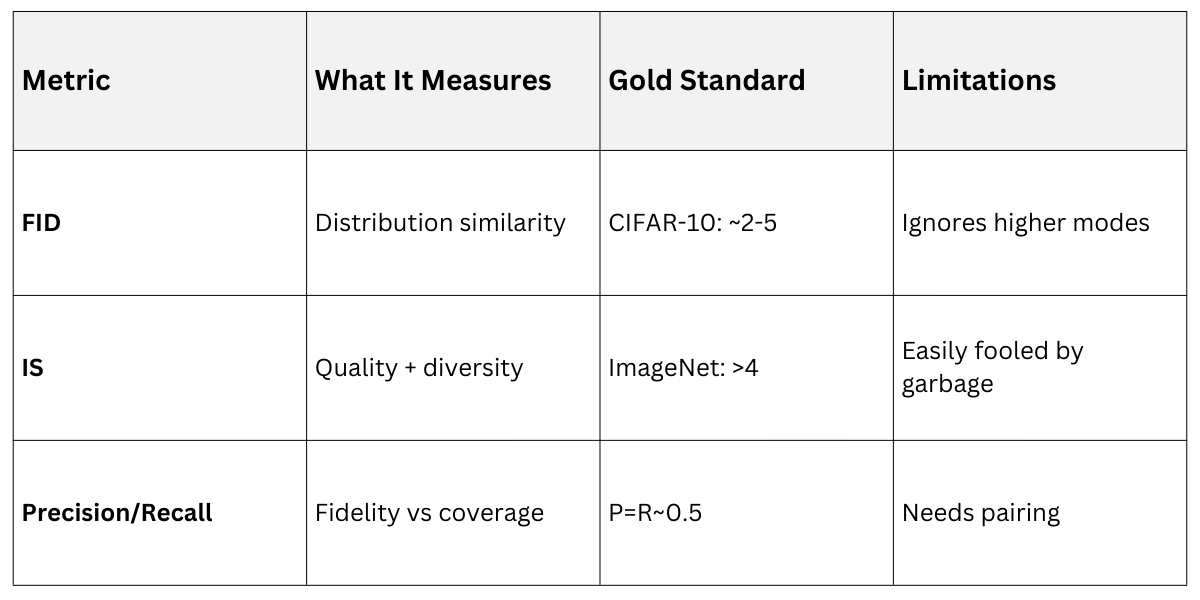 Human Evaluation Protocols
Human Evaluation Protocols
Automated metrics correlate imperfectly with preference—humans remain the ultimate judge.
Standard Protocols:
1. 2AFC (Two-Alternative Forced Choice): "Pick the real image" (70%+ accuracy = good).
2. Likert Scale: 1-5 ratings for realism/diversity.
3. Pairwise Ranking: A/B preference for prompts.
Scaling with Crowdsourcing
# Pseudo-code for MTurk setup
trials = [
{"real": img1, "fake": img2, "prompt": "Delhi skyline"},
# ... 1000s more
]
human_pref = aggregate_votes(trials) # >60% human pref = production-readyIndustry Standard: OpenAI's DrawBench uses 200+ prompts with human Likert scores alongside FID.
Example: Stable Diffusion v2.1 scores FID=12 on MS-COCO but 75% human preference after prompt engineering.
