The historical evolution of generative models reflects the rapid progress in how machines learn to create data. Early breakthroughs were driven by Generative Adversarial Networks, which introduced an adversarial training framework capable of producing highly realistic samples.
Over time, limitations in training stability and evaluation led to the exploration of alternative approaches, including diffusion models and transformer-based architectures, each offering improved control, scalability, and performance across different data modalities.
GANs: The Pioneers of Adversarial Generation
GANs, introduced by Ian Goodfellow in 2014, marked the dawn of modern generative modeling by pitting two neural networks against each other. This adversarial setup revolutionized image synthesis but faced hurdles like unstable training.
GANs consist of a generator that creates fake data and a discriminator that spots fakes, training in a minimax game until the generator fools the discriminator perfectly. Early successes like DCGANs (2015) showed crisp 64x64 images, but issues persisted.
Key Milestones
1. 2014: Vanilla GAN – Basic framework; prone to mode collapse (generator produces limited varieties).
2. 2016: DCGAN – Convolutional layers for stable, high-quality faces and objects.
3. 2017: Progressive GAN – Trained at increasing resolutions, enabling photorealistic 1024x1024 images (e.g., NVIDIA's human faces).
Despite flaws, GANs powered tools like DeepFakes and StyleGAN (2019), which used style-based generation for editable facial attributes—practical for avatar creation in apps.
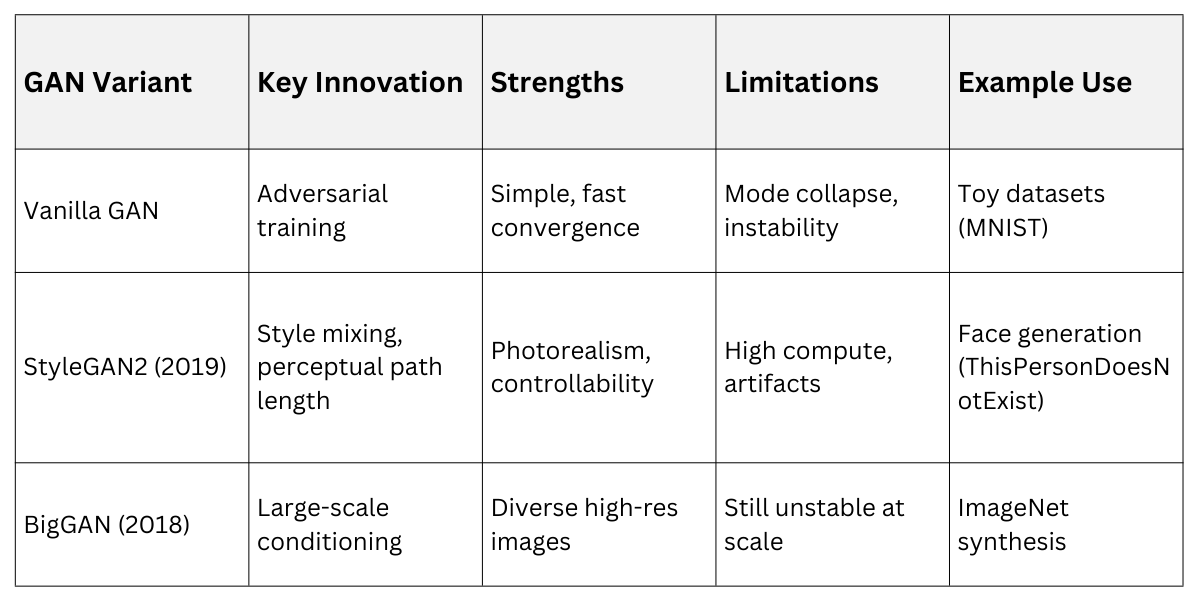
GANs set the stage but couldn't scale reliably to complex distributions, paving the way for non-adversarial alternatives.
Diffusion Models: From Denoising to Photorealism
Diffusion models emerged around 2015 but exploded in popularity post-2020, offering stable training without adversaries. They work by gradually adding noise to data (forward diffusion) and learning to reverse it (denoising), producing samples from pure noise.
This probabilistic approach avoids GANs' pitfalls, yielding sharper, more diverse outputs. By 2022, models like Denoising Diffusion Probabilistic Models (DDPM) outperformed GANs on benchmarks like FID scores for image quality.
Practical Workflow
-Picsart-CropImage.png)
Denoising Diffusion Implicit Models (DDIM, 2020) sped this up to 10-50 steps. OpenAI's DALL·E 2 (2022) and Stable Diffusion (2022, from Stability AI) integrated text conditioning via CLIP, enabling prompts like "a cyberpunk Delhi skyline at dusk."
Recent Advances (2024-2026)
1. Latent Diffusion: Operate in lower-dimensional latent space (e.g., Stable Diffusion XL) for efficiency on consumer GPUs.
2. Consistency Models (2023): Single-step generation, rivaling multi-step diffusion.
3. Flow Matching (2024): Straight trajectories for faster training.
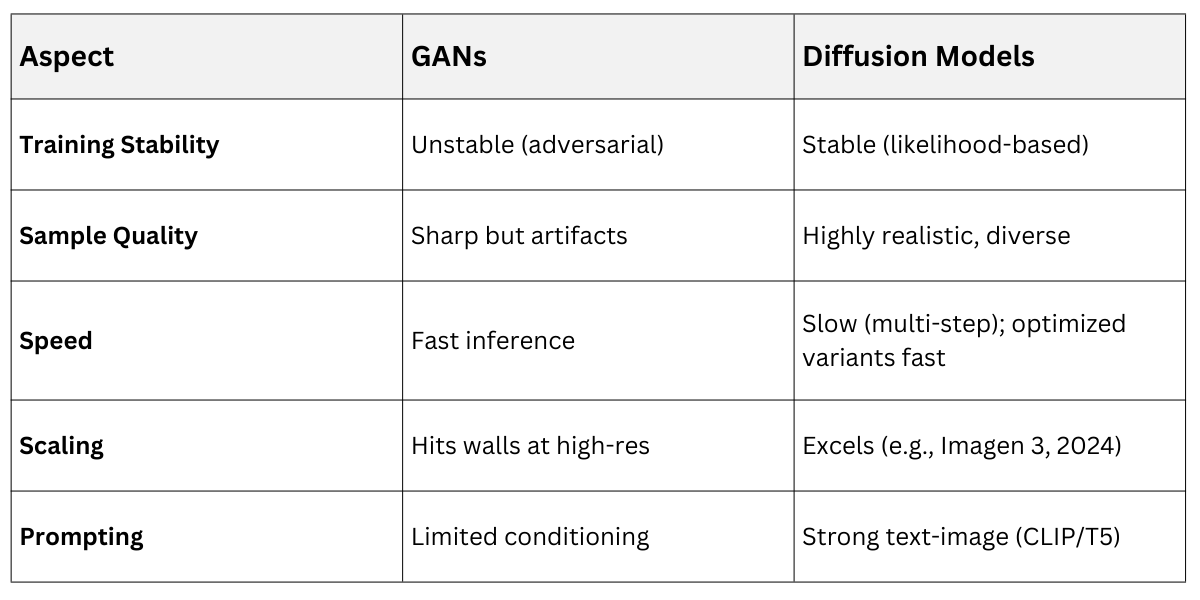
Diffusion's reliability made it the backbone of tools like Midjourney, ideal for your course projects in data visualization or educational content generation.
Transformer-Based Generative Models: Scaling to Multimodality
Transformers, born from "Attention is All You Need" (2017), shifted generative AI toward autoregressive, scalable architectures. In generation, they excel at sequence modeling, powering text (GPT series) and extending to images/videos via patches.
By 2021, Vision Transformers (ViT) tokenized images into patches, enabling diffusion-transformer hybrids. This evolution unified modalities, supporting prompts across text, image, and video.
Core mechanism: Self-attention weighs token importance:
Attention(Q,K,V) = softmax(QKᵀ / √dₖ) V. For generation, models predict next tokens autoregressively.
Key Developments
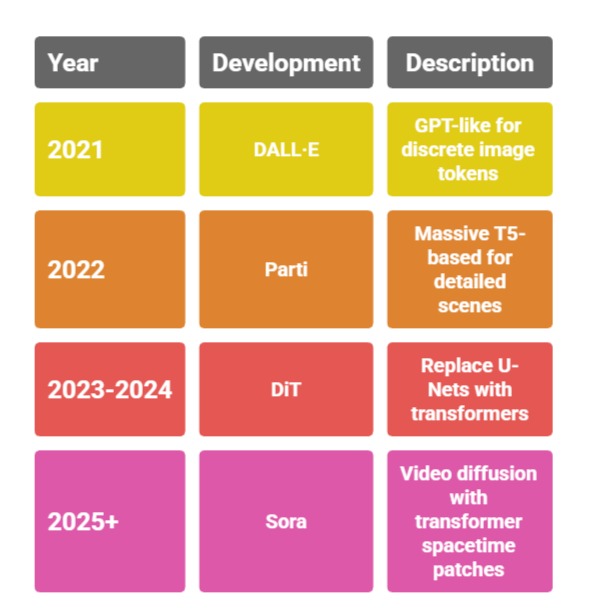
Practical example: In Stable Diffusion 3 (2024), a Multimodal Diffusion Transformer (MMDiT) handles text+image inputs, outputting 1MP images. Prompt: "Historical Delhi Red Fort in cyberpunk style" yields editable, high-fidelity results—perfect for web dev prototypes.
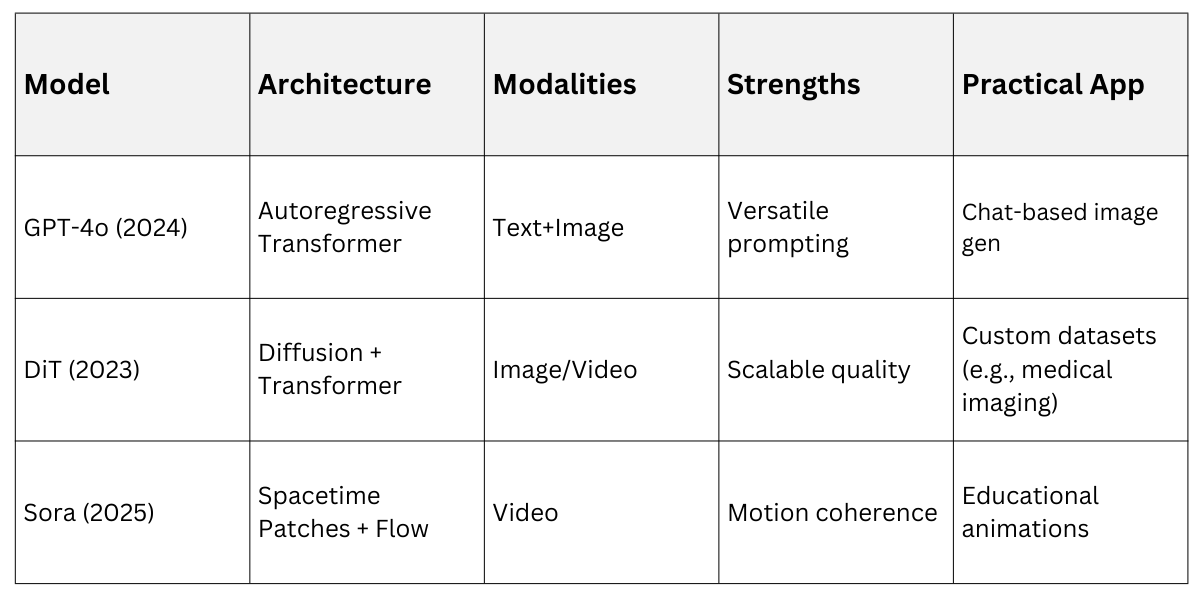
Transformers' attention scales with data/compute, dominating 2026 benchmarks (e.g., GenAI Leaderboard).
Hybrids and the Current Landscape
No evolution stops—hybrids blend strengths: GANs for sharpness, diffusion for diversity, transformers for scale. Examples include GANs as denoisers (2024) and Transfusion (2025), merging all three for 10x faster video gen.
Convergence Powers Production Tools:
1. Runway ML Gen-3 (2025): DiT-diffusion for film-quality video.
2. Adobe Firefly 3 (2026): Commercial-safe, transformer-conditioned diffusion.
For prompt design in our course, hybrids shine: Use descriptive, iterative prompts like "Refine: Add Delhi traffic to cyberpunk fort, high detail."

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.