Audio and video generation are rapidly advancing areas of generative AI that focus on creating realistic sound and visual sequences from prompts or input data.
Models such as AudioLDM generate high-quality audio by applying diffusion techniques in latent audio spaces, enabling efficient sound synthesis from text or other conditions.
For video generation, models like Phenaki and the principles behind Sora emphasize generating long, coherent video sequences by modeling both spatial and temporal dynamics.
These systems combine transformers, diffusion models, and strong representations to maintain consistency across time while producing realistic multimedia content.
Core Principles of Generative Audio and Video
At the heart of these models lies diffusion processes, where noise is iteratively added to data and then reversed to generate new samples.
This shared foundation allows seamless text-to-audio or text-to-video translation, often powered by large language models (LLMs) for conditioning.
We'll break down key concepts before diving into specific architectures, emphasizing how they scale from audio waveforms to complex video scenes.
Diffusion Models: The Backbone
Diffusion models operate by corrupting data with noise over multiple steps, then training a neural network to denoise it step-by-step, reconstructing realistic outputs.
This approach excels in latent space a compressed representation of data reducing computational demands while preserving quality. For audio and video, it handles high-dimensional data like waveforms or pixel frames efficiently.
.png)
Practical Example: In video generation, this creates smooth motion by diffusing frame sequences, ensuring temporal consistency across seconds of footage.
Audio Generation Architectures
Audio generation focuses on synthesizing waveforms or spectrograms from text, tackling challenges like timbre, rhythm, and emotional nuance. Models like AudioLDM pioneer efficient, text-conditioned pipelines.
AudioLDM: Latent Diffusion for Sound
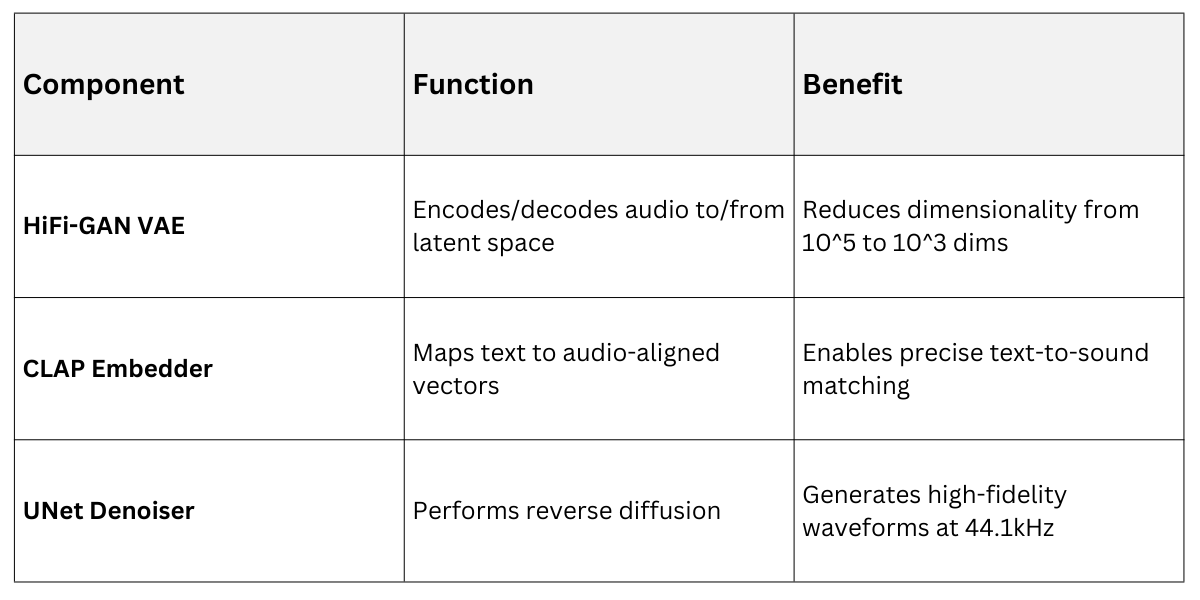
AudioLDM (Audio Latent Diffusion Model) compresses raw audio into a latent space using a HiFi-GAN encoder, then applies diffusion there for faster training.
It conditions generation on CLAP embeddings—contrastive language-audio pretraining—to align text descriptions with sound features. This results in diverse outputs like "thunderstorm with distant echoes" from natural language.
Key Features
1. Efficiency: Latent diffusion cuts training time by 90% compared to pixel-space methods.
2. Controllability: Prompt engineering refines attributes like pitch or intensity.
3. Applications: Music generation, sound effects for games, or voiceovers.
To implement a basic AudioLDM inference (pseudocode for illustration):
1. Encode text prompt to CLAP embedding.
2. Initialize latent noise tensor.
3. For t in diffusion_steps:
- Predict noise with UNet (conditioned on embedding).
- Denoise latent step.
4. Decode latent to waveform with HiFi-GAN.Best Practice: Use descriptive prompts like "upbeat jazz saxophone solo with reverb" for nuanced control.
Video Generation Architectures
Video synthesis extends diffusion to spatiotemporal data, ensuring temporal consistency (smooth motion) and spatial realism (sharp details). Models like Phenaki and Sora address long-sequence challenges.
Phenaki: Scalable Text-to-Video Diffusion
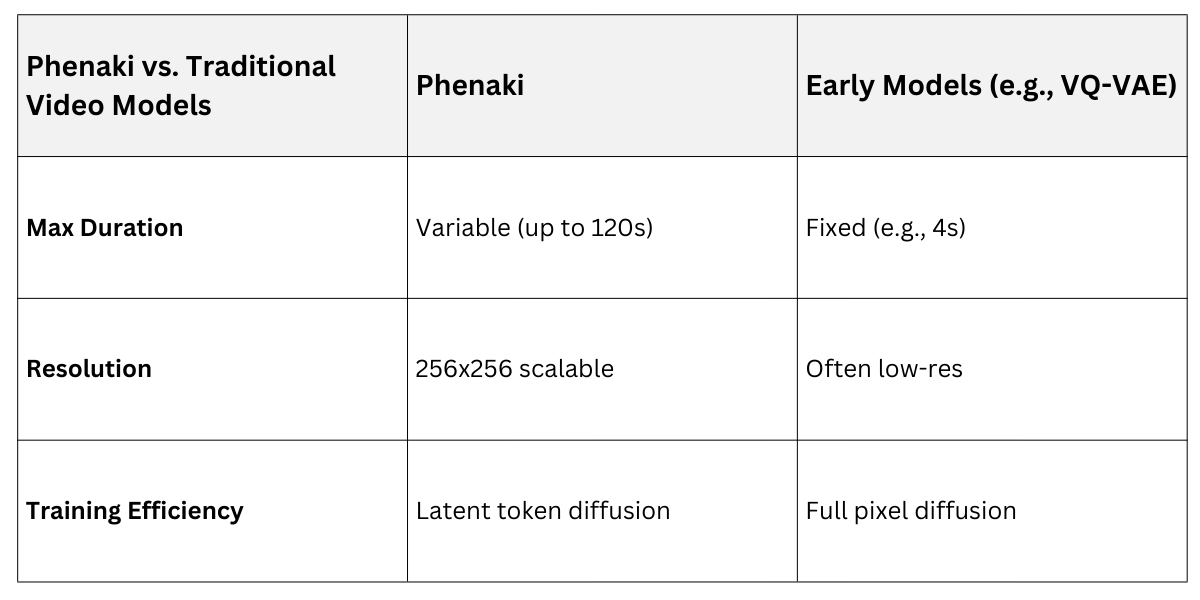
Phenaki, from Google Research, uses a masked multimodal VAE to tokenize video into compact patches, enabling diffusion on variable-length clips up to 2 minutes.
It employs temporal UNet layers with 3D convolutions for motion modeling, conditioned via T5 text encoder. This handles diverse durations without fixed-frame limits.
1. Tokenization: Videos become sequences of visual tokens, like words in NLP.
2. Scalability: Trains on web-scale data for generalization to unseen scenes.
Prompt design Tip: Specify duration and style, e.g., "A cat chasing a laser pointer for 10 seconds in slow motion."
 Sora: World Simulation Through Video
Sora: World Simulation Through Video
OpenAI's Sora (2024 release) simulates physics-based worlds via a space-time latent diffusion model, generating minute-long videos at 1080p from text.
It uses video compression into spacetime patches (DiT architecture), with flow matching for realistic motion prediction. Multiple patch-level conditioning ensures global coherence.
Core Principles
1. Patchification: Divide video into space-time patches (e.g., 3x3x9 pixels x time).
2. DiT Transformer: Diffusion Transformer processes patches with text via cross-attention.
3. Variational scaling: Upscales latents for high-res output.
Highlights from Sora's Capabilities
1. Physics awareness: Generates accurate interactions like "rippling water from a stone skip."
2. Multi-shot consistency: Maintains character identity across camera angles.
3. Prompt best practices: Combine scene description, motion verbs, and style (e.g., "Aerial drone shot of Tokyo at dusk, bustling streets with neon lights flickering, cinematic 4K").
Prompt Design Strategies for Audio and Video
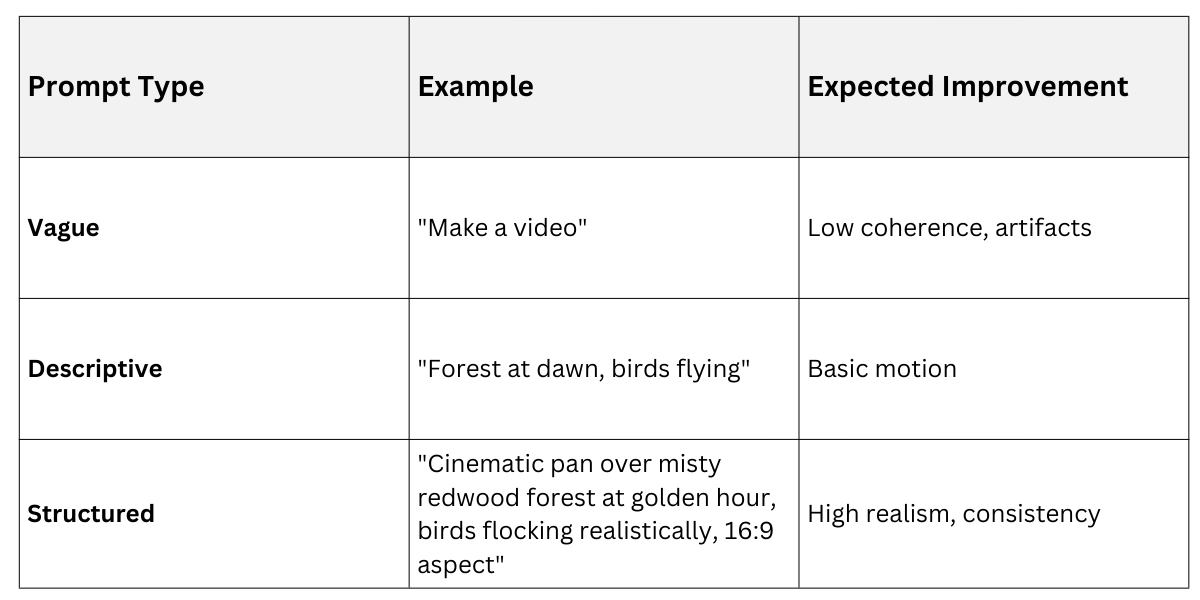
Effective prompts turn vague ideas into precise generations—specificity drives quality.
For audio: Layer attributes hierarchically
1. Start with genre/mood: "Ethereal ambient synth."
2. Add details: "...with rising arpeggios and soft reverb."
3. Specify length/tempo: "...30 seconds at 120 BPM."
For video: Structure as scene-motion-style
1. Scene: "Snowy mountain peak."
2. Motion: "...avalanche cascading down in slow motion."
3. Style/Camera: "...dramatic wide-angle shot, Pixar-inspired."
Experiment Iteratively: Generate, refine prompts based on outputs, and chain models (e.g., AudioLDM sound + Sora video).
Practical Applications and Best Practices
These models power industries beyond creativity.
1. Content Creation: Auto-generate promo videos with synced audio.
2. Education/Simulation: Procedural training videos for medicine or driving.
3. Accessibility: Text-to-audio descriptions for visually impaired users.
Best Practices
.png)
Hands-on Tip: Fine-tune AudioLDM on domain-specific audio (e.g., Indian classical ragas) using Hugging Face Diffusers library.
