Test-time training and adaptive compute are techniques designed to improve model performance and efficiency during inference rather than training.
Test-time training allows a model to adapt its parameters or internal representations on-the-fly using incoming test data, enabling better generalization to distribution shifts.
Adaptive compute methods dynamically allocate computational resources based on task complexity.
Techniques such as speculative decoding accelerate text generation by using a smaller draft model to propose tokens that are selectively verified by a larger model, reducing latency.
MAD (Mixture of Adaptive Depths) further optimizes inference by adjusting the number of layers or computation steps used per input, balancing speed and accuracy.
Test-Time Training: Rethinking Inference as Learning
Test-time training flips the traditional paradigm by treating inference as a lightweight learning process. Rather than using a static model, it adapts dynamically to each input using small amounts of compute during deployment.
This approach shines in generative AI where prompts vary widely and contexts shift rapidly. Here's how it transforms model behavior at runtime.
Core Principles of Test-Time Adaptation
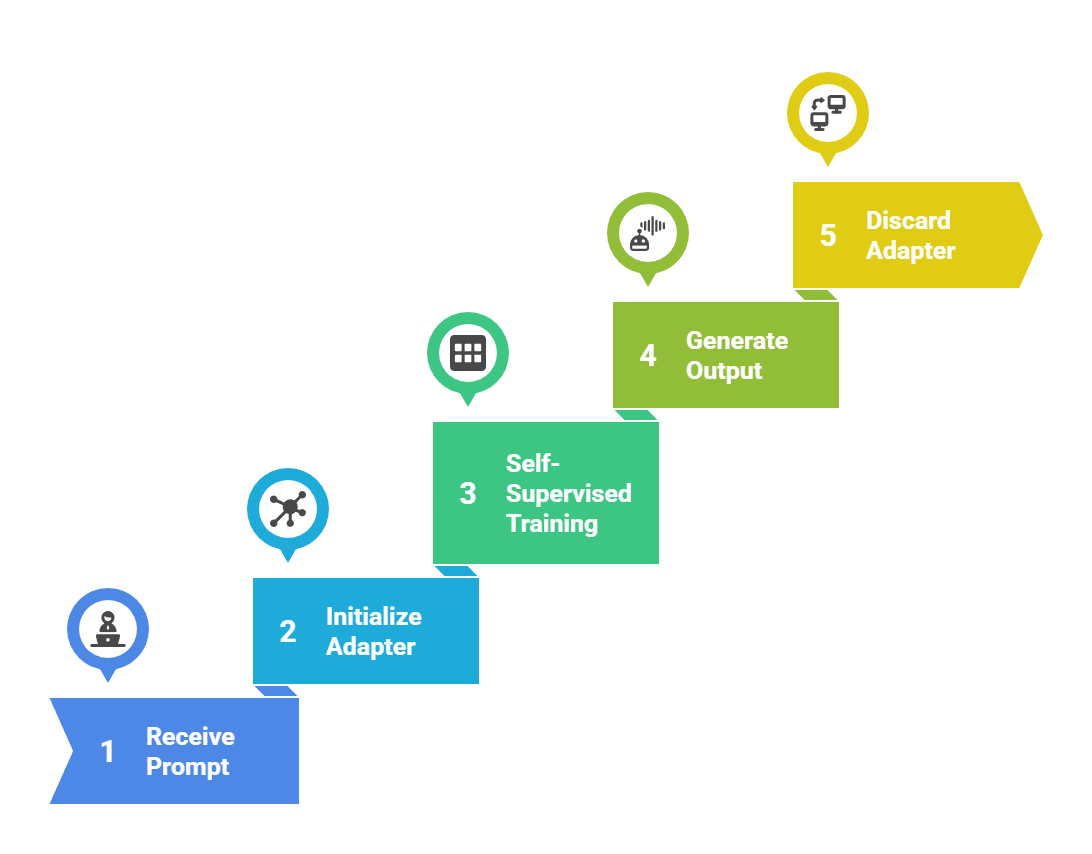
Test-time training leverages the model's existing knowledge but fine-tunes a lightweight adapter or auxiliary network for each specific input. The process runs entirely during inference, requiring no labeled data.
1. Input-specific adaptation: Model observes the prompt and generates task-specific embeddings
2. Gradient-based updates: Performs 1-5 training steps on self-supervised losses
3. No parameter storage: Changes are ephemeral and discarded after each inference
Practical workflow
 This enables models to specialize for niche prompts—like medical Q&A or legal analysis—without full retraining.
This enables models to specialize for niche prompts—like medical Q&A or legal analysis—without full retraining.
Real-World Applications and Case Studies
Consider a customer support chatbot handling diverse queries. Standard models struggle with domain shifts (tech support vs. billing), but test-time training adapts in <100ms.
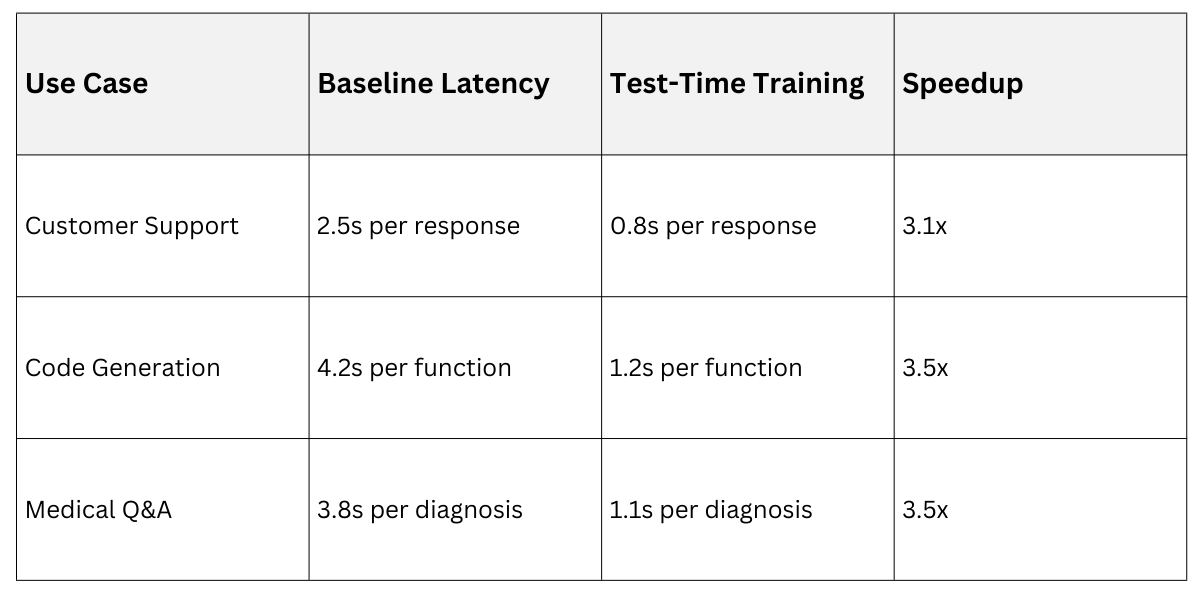
Key Insight: The technique excels when prompts contain rich context, allowing the model to "self-teach" from the input itself.
Adaptive Compute: Intelligence in Resource Allocation
Adaptive compute dynamically adjusts computational resources based on input complexity and desired quality. Instead of fixed token-by-token generation, it scales effort intelligently.
These methods prevent overkill on simple prompts while investing more compute where needed. They form the backbone of production-grade generative AI systems.
Speculative Decoding: Parallel Speed Boost
Speculative decoding predicts multiple tokens simultaneously, verifying them in batch. A smaller "draft" model proposes candidates, while the main model checks them in parallel.
This creates a draft-and-verify pipeline that's 2-5x faster than standard autoregressive decoding.
Core Algorithm:
1. Main model generates first token T1
2. Draft model speculates next N tokens: T2, T3, ..., TN+1
3. Main model verifies all N tokens in parallel
4. Accept longest correct prefix, repeat from mismatch pointImplementation example (PyTorch pseudocode)
def speculative_decode(main_model, draft_model, prompt, max_tokens):
output = generate_first_token(main_model, prompt)
while len(output) < max_tokens:
draft_tokens = draft_model.generate(output, n=8) # Speculate 8 tokens
verified = main_model.verify_batch(output + draft_tokens)
output.extend(verified[:len(verified)-1]) # Accept prefix
if not verified[-1]: break # Mismatch detected
return outputProduction Benefits
1. GPU utilization: 80-95% vs. 20-40% in standard decoding
2. Latency consistency: Predictable response times
3. Hardware agnostic: Works across TPUs, GPUs, even CPUs
Mixture of Agents Decoding (MAD): Collaborative Intelligence
MAD runs multiple specialized "agents" (smaller models or model heads) in parallel, combining their outputs intelligently. Each agent specializes in different generation patterns.
Architecture Overview:
├── Agent 1: Creative writing specialist
├── Agent 2: Factual accuracy checker
├── Agent 3: Code generation expert
└── Router: Selects/combines based on prompt analysisDynamic Routing Process
1. Prompt classifier: analyzes input characteristics
2. Agent selection: Chooses 2-4 optimal agents from pool of 8+
3. Parallel generation: Agents work simultaneously
4. Mixture aggregation: Weighted combination via learned gating network
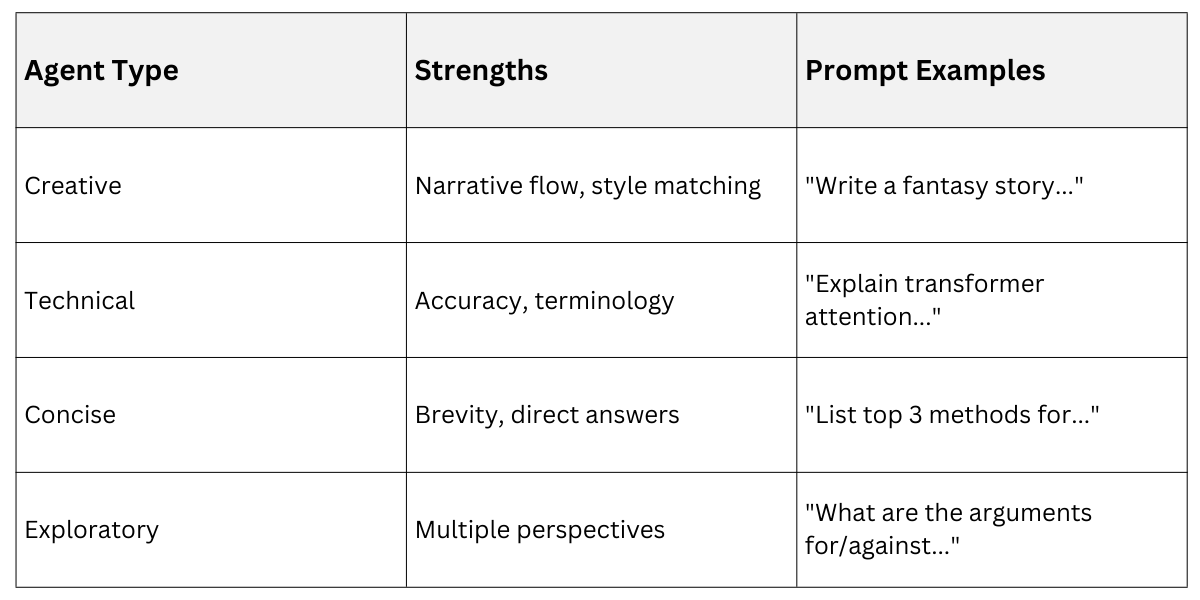
Key Advantage: MAD adapts compute to task complexity. Simple prompts use 1 agent (fast), complex prompts leverage 4+ agents (high quality).
Comparing Optimization Strategies
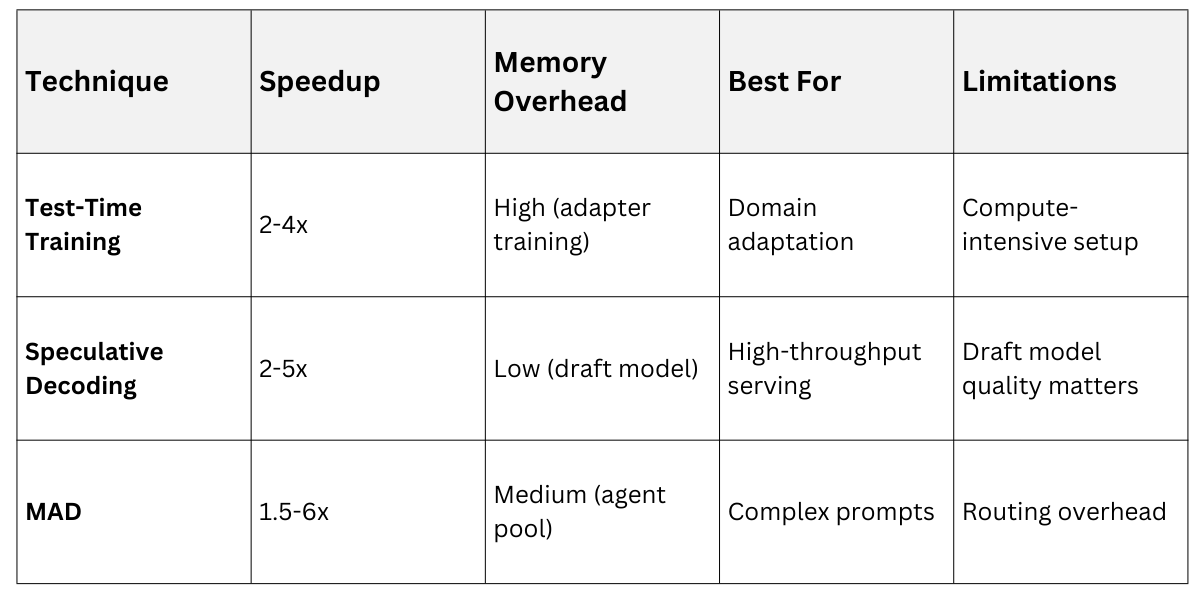
Selection Guide
1. High-volume APIs: Speculative decoding
2. Domain-specific apps: Test-time training
3. Interactive tools: MAD (balances speed/quality)
Implementation Best Practices
Deploying these techniques requires careful system design. Here are proven strategies from production deployments.
Infrastructure Considerations
Hardware optimization:
1. Use tensor parallelism for agent pools in MAD
2. Enable flash attention for speculative verification
3. Deploy draft models on edge TPUs for latency
Code Deployment Pattern
class AdaptiveGenerator:
def __init__(self):
self.main_model = load_main_model()
self.draft_model = load_draft_model()
self.agents = load_agent_pool()
self.test_time_adapter = TestTimeAdapter()
def generate(self, prompt, strategy="auto"):
if strategy == "speculative":
return speculative_decode(self.main_model, self.draft_model, prompt)
elif strategy == "mad":
return mad_decode(self.agents, prompt)
else:
return self.test_time_adapter.generate(self.main_model, prompt)Monitoring and Optimization
Track these key metrics:
1. Time-to-first-token (critical for UX)
2. Tokens-per-second (throughput)
3. Acceptance rate (speculative decoding quality)
4. Agent utilization (MAD efficiency)
Continuous Improvement Loop
.png)

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.