Scaling laws, mixture-of-experts architectures, and efficient inference techniques are key concepts in building and deploying large language models.
Scaling laws describe how model performance improves as parameters, data, and compute increase, guiding decisions about model size and training resources.
Mixture-of-experts architectures divide a model into multiple specialized sub-networks, activating only a subset for each input to improve scalability and efficiency.
Efficient inference techniques such as key–value caching and quantization reduce computational and memory costs during model execution.
Scaling Laws in Generative AI
Scaling laws provide a roadmap for predicting how model performance improves with more compute, data, and parameters, guiding efficient resource allocation in LLM development.
These empirical rules, pioneered by researchers at OpenAI, help architects decide when to scale up rather than redesign from scratch.
Origins and Key Principles
Scaling laws emerged from analyzing thousands of training runs on models like GPT-3. They reveal predictable relationships between model size, dataset volume, and compute budget on one hand, and loss (a proxy for performance) on the other.
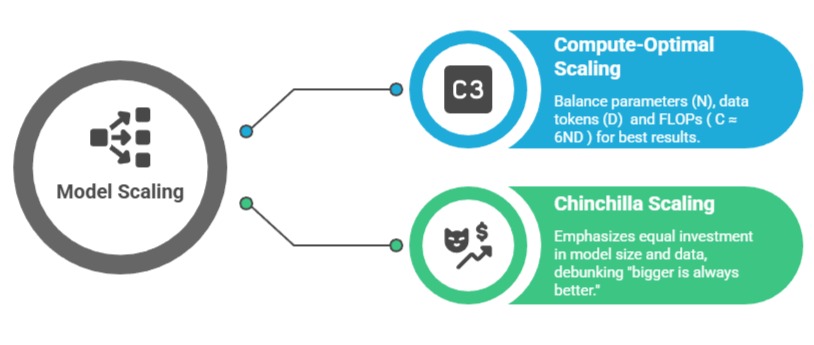
For example, training a 70B-parameter model like Llama 2 required scaling data to trillions of tokens, achieving better results than naively up-sizing parameters.
Practical Applications and Trade-offs
In generative AI, scaling laws inform decisions for tasks like prompt-based content generation.
Key insight: Performance follows a power-law curve—doubling compute often yields consistent gains, but with diminishing returns past certain thresholds.
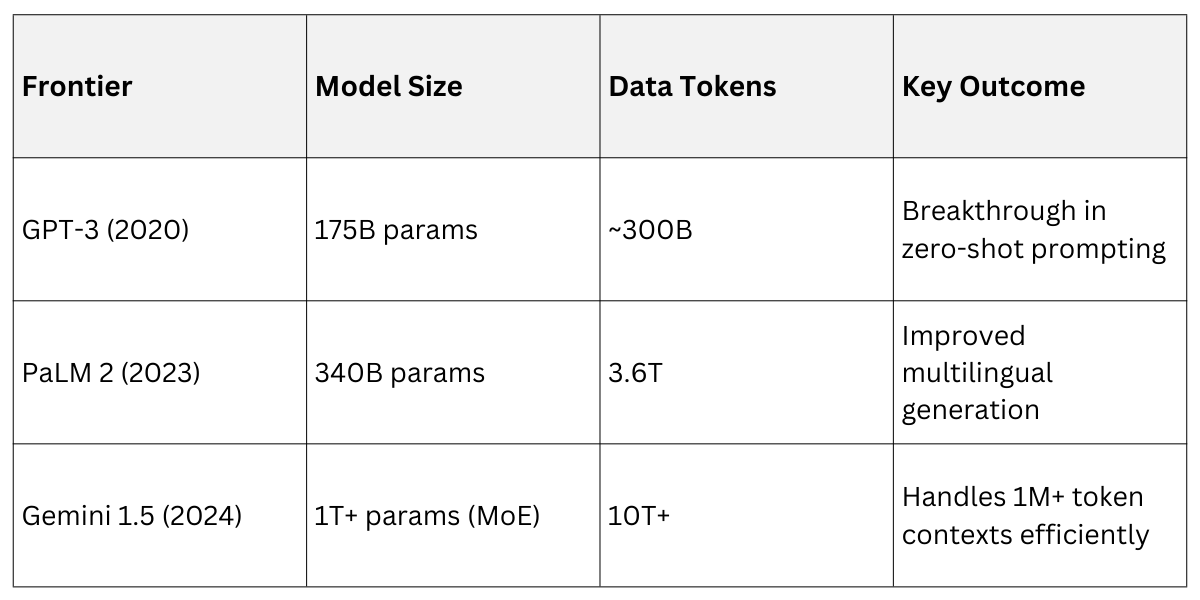
Trade-offs: While scaling boosts capabilities (e.g., better reasoning in long prompts), it spikes costs—training a 1T-param model can exceed $100M. Best practice: Use laws to hybridize with MoE for "scaling without the full bill."
Mixture-of-Experts (MoE) Architectures
Mixture-of-Experts (MoE) layers activate only a subset of "expert" sub-networks per token, slashing compute while rivaling dense models in performance.
This sparsity technique scales models to trillions of parameters affordably, making it ideal for generative tasks needing vast knowledge without dense overhead.
Core Mechanics of MoE
In a transformer layer, MoE replaces the feed-forward network (FFN) with a router that picks top-k experts (usually k=2) from many (e.g., 8-128).
The router, often a simple MLP, learns to dispatch tokens to specialized experts during training.
1. Token embedding enters the MoE layer.
2. Router scores each expert for affinity.
3. Top-k selection: Activate only those experts; others stay idle.
4. Weighted combination of expert outputs forms the layer result.
Code snippet (PyTorch-like pseudocode for clarity)
def moe_layer(hidden_states, num_experts=8, top_k=2):
router_logits = router(hidden_states) # [batch, seq, num_experts]
topk_logits, topk_ids = torch.topk(router_logits, top_k)
# Dispatch to experts and combine
expert_outputs = [experts[i](hidden_states) for i in topk_ids]
return combine(expert_outputs, topk_logits.softmax(-1))Mixtral 8x7B (Mistral AI, 2024) exemplifies this: 47B total params but activates ~13B per forward pass, matching GPT-3.5 quality at 5x speed.
Advantages for Generative AI and Real-World Examples
MoE shines in prompt design for diverse tasks—experts specialize in code, math, or language, improving output quality.
Benefits include
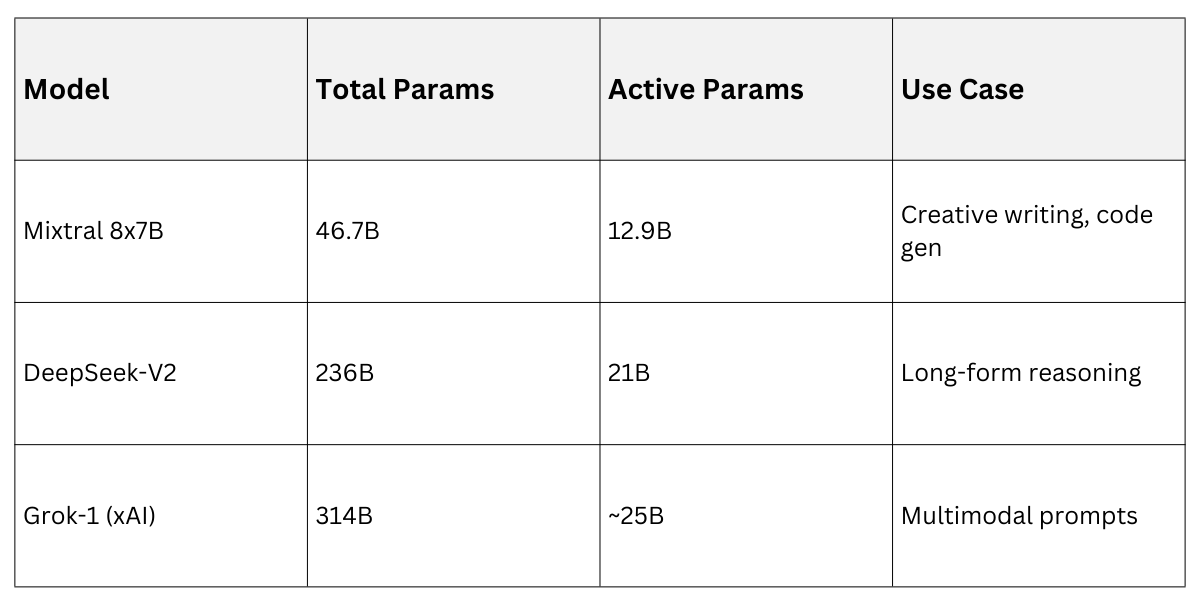
Practical Tip: In your course projects, use Hugging Face's MoE implementations to prototype sparse models for efficient local deployment.
Efficient Inference Techniques
Inference—the phase where trained models generate responses—often bottlenecks deployment due to latency and memory demands.
Techniques like KV caching and quantization optimize this, enabling real-time generative AI on edge devices without retraining.
KV Caching for Speed
In autoregressive generation, transformers recompute keys (K) and values (V) for all prior tokens each step—a quadratic waste.
KV caching stores past K/V pairs, appending only new ones, cutting compute from O(n²) to O(n) per token.
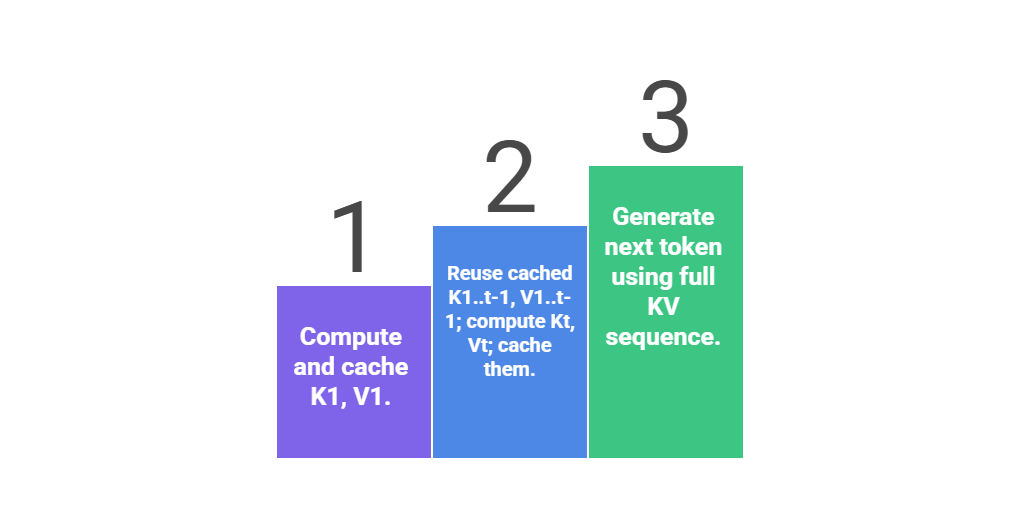
This powers ChatGPT's fluidity: A 100-token prompt generates 50 continuations in milliseconds vs. seconds without cache.
PagedAttention (vLLM framework, 2024 standard) extends it with virtual memory, handling 1M+ contexts without OOM errors.
Quantization for Memory and Speed: Quantization compresses weights from 16-bit floats (FP16) to lower precision (e.g., 4-bit), shrinking models 4x while preserving >95% accuracy.
Post-training quantization (PTQ) applies statically; quantization-aware training (QAT) bakes it in.
Common Methods
1. GPTQ / AWQ: Per-channel scaling for LLMs, used in TheBloke's quantized Llama models.
2. 4-bit NF4: NormalFloat4, optimal for generative tasks per NVIDIA's TensorRT-LLM.
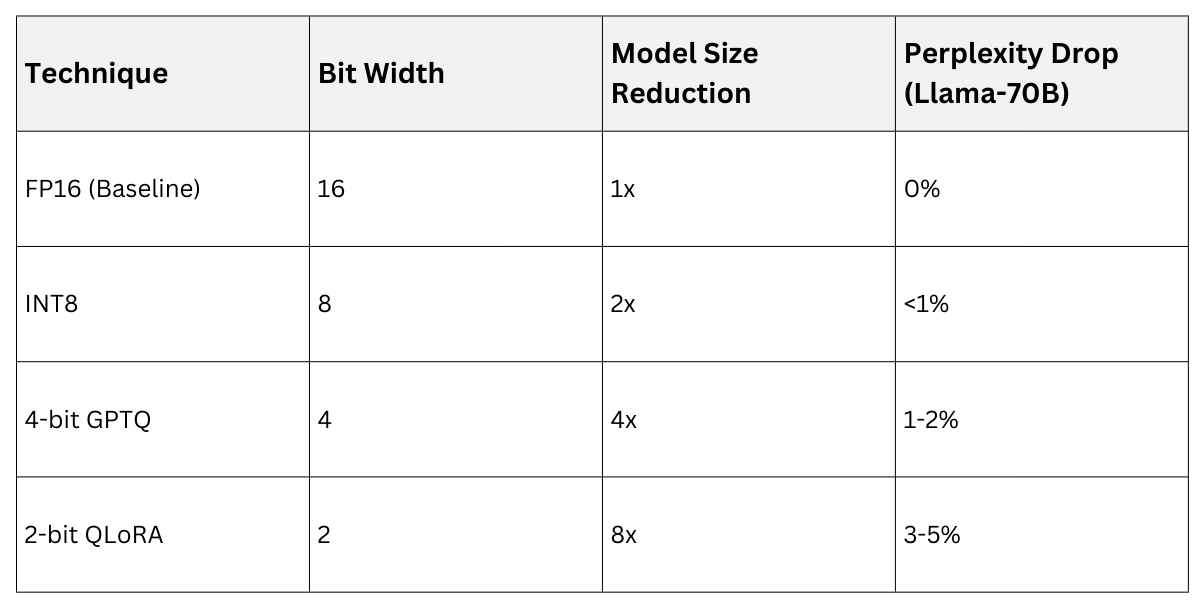
Example: Quantized Mixtral runs on a single RTX 4090 GPU, generating code prompts at 50+ tokens/sec—vital for web apps.
Best Practice: Combine with KV cache in frameworks like vLLM or ExLlama for 10x throughput gains

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.