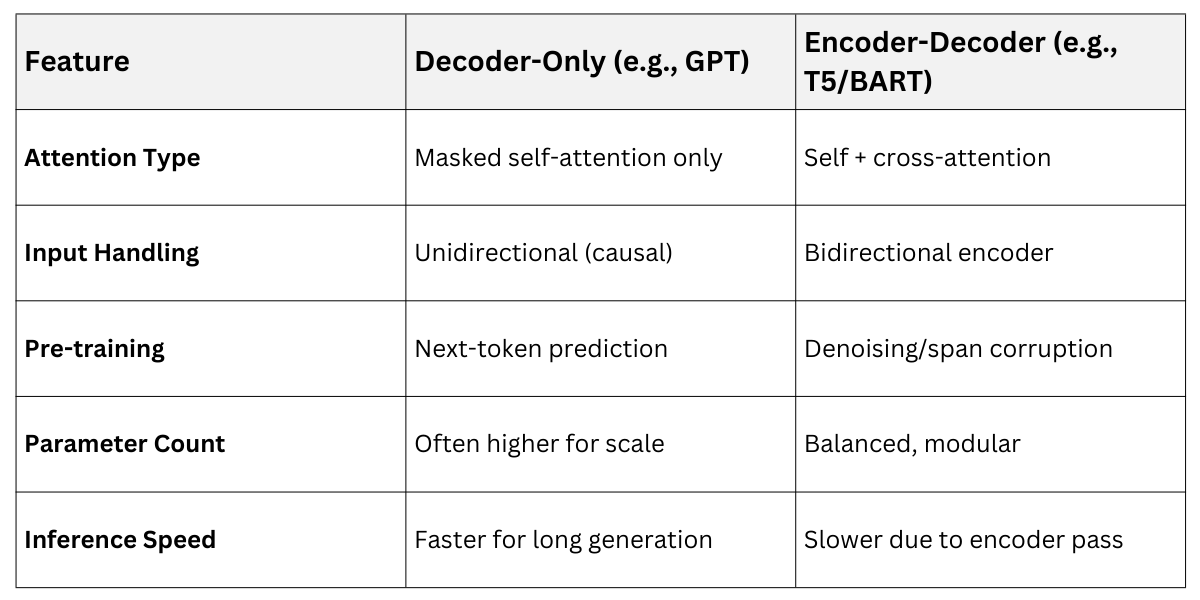
Decoder-only and encoder–decoder architectures represent two major design approaches in transformer-based models. Decoder-only architectures generate text autoregressively by predicting the next token based on previous tokens, making them well suited for language modeling and open-ended text generation.
Encoder–decoder architectures, such as T5 and BART, separate input understanding and output generation into two stages, allowing the model to transform an input sequence into a different output sequence.
Decoder-Only Architectures
Decoder-only models, popularized by the GPT family, rely on a single stack of decoder layers to handle both input processing and output generation.
They excel in autoregressive tasks where the model predicts the next token based solely on previous ones, making them streamlined for open-ended generation.
Core Mechanics and Self-Attention
At their heart, decoder-only models use masked self-attention, which ensures the model only "sees" previous tokens during training and inference. This unidirectional flow mimics human writing, where you build text sequentially without peeking ahead.
Key Components
.png)
This setup shines in tasks like story completion. For instance, prompting "Once upon a time" with GPT-4 generates coherent continuations because it conditions every new token on the full prior context.
Strengths and Use Cases: Decoder-only architectures are lightweight and scalable, training on massive datasets via next-token prediction. They're ideal for zero-shot or few-shot learning, where prompts guide behavior without fine-tuning.
Decoder-Only Models: Advantages & Examples
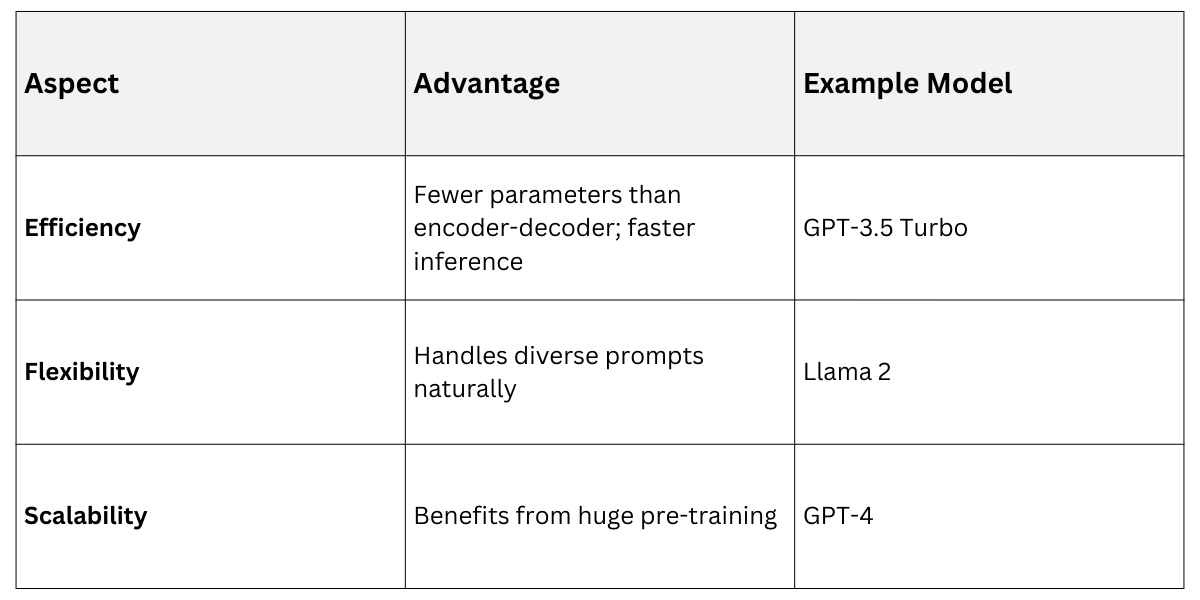
Practical example: In prompt design, use them for creative tasks. Prompt: "Write a poem about AI in haiku form:" yields structured output because the model autoregressively builds line by line.
Limitations: Despite their power, decoder-only models struggle with tasks requiring deep bidirectional context, like filling gaps in text (e.g., cloze tests). They can't easily "re-read" the entire input symmetrically, leading to potential inconsistencies in long sequences.
Encoder-Decoder Architectures
Encoder-decoder models, like T5 (Text-to-Text Transfer Transformer) and BART, split responsibilities: the encoder processes the full input bidirectionally, while the decoder generates output autoregressively.
This duo enables nuanced understanding and generation, perfect for seq2seq tasks.
How They Work: Encoder and Decoder Interplay
The encoder uses full self-attention to capture bidirectional relationships across the input, creating rich representations. The decoder then attends to these via cross-attention, blending source and target information.
Follow these Steps in a Typical Forward Pass
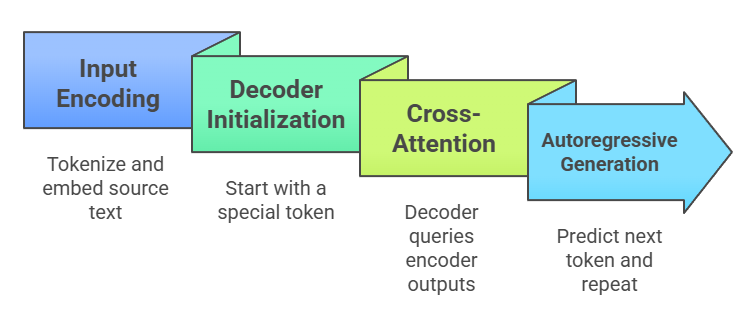
Example: In T5, "translate English to French: Hello world" becomes "Bonjour le monde." The encoder grasps "Hello world" fully, guiding the decoder precisely.
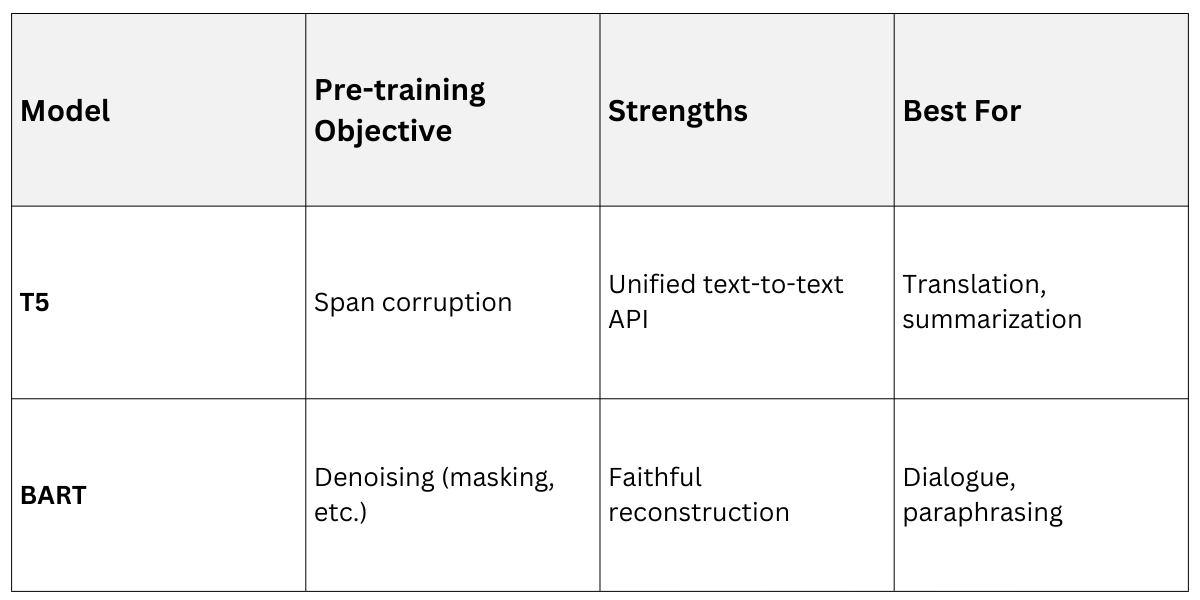
Key Models: T5 and BART
T5 frames all tasks as text-to-text, prefixing inputs (e.g., "summarize: [text]"). It's pre-trained on span corruption, masking random spans and predicting them.
BART combines BERT-style pre-training (bidirectional) with GPT-style generation, using denoising objectives like token masking or sentence permutation.
Both support fine-tuning; T5's latest variants (e.g., T5-11B) incorporate adapter tuning for efficiency.
Strengths and Practical Applications
Encoder-decoder shines in conditional generation, where output must closely mirror input structure. They're robust for editing tasks, leveraging bidirectional encoding.
Advantages
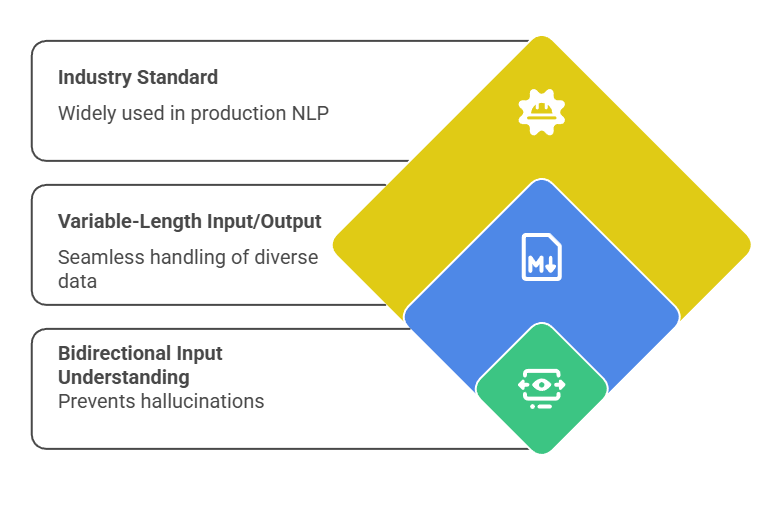
Prompt Tip: Prefix tasks clearly, as in "ql: [question] context: [text]" for question-answering, aligning with their text-to-text paradigm.
Direct Comparison: Choosing between architectures depends on your task's needs—decoder-only for free-form creativity, encoder-decoder for precise transformations.
Architectural Differences
Decoder-only is simpler (one stack), while encoder-decoder doubles up for richer context.
Task Suitability and Prompt Design Implications
Decoder-only wins for:
1. Chat/completion (e.g., "Continue this story:").
2. Code generation.
3. Open-ended QA.
Encoder-decoder excels in
1. Summarization (input text → concise output).
2. Translation.
3. Text editing (e.g., "fix grammar: [flawed text]").
In prompt design, decoder-only thrives on conversational chains; encoder-decoder needs structured prefixes.
Best Practice: Hybrid workflows, like using GPT for ideation and T5 for refinement.
Performance Benchmarks: Recent benchmarks (e.g., GLUE, SuperGLUE as of 2024) show encoder-decoder edging out on extractive tasks (BART: 87% on CNN/DailyMail summarization), while decoder-only dominates generative benchmarks (GPT-4: 90%+ on MMLU).

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.