As large language models are increasingly used in high-stakes and production environments, reliable evaluation and error detection have become essential.
Robust evaluation frameworks such as LLM-as-Judge and G-Eval leverage language models themselves to assess output quality, coherence, relevance, and reasoning.
Alongside evaluation, hallucination detection techniques aim to identify and reduce factually incorrect or unsupported model outputs, improving trustworthiness and safety.
LLM-as-a-Judge Fundamentals
LLM-as-a-judge leverages a powerful large language model, often GPT-4 or similar, to score or rank outputs from other generative models automatically.
This approach mimics human evaluation but scales efficiently, making it ideal for high-volume testing during development.
Traditionally, evaluating text relied on metrics like BLEU or ROUGE, which compare strings but miss nuance like coherence or creativity. LLM-as-a-judge overcomes this by understanding context deeply, providing scores with explanations.
For instance, when assessing a chatbot response, it might rate helpfulness on a 1-10 scale while noting strengths in empathy.
Key Benefits Include
.png)
How LLM-as-a-Judge Works
The process treats the evaluator LLM as an impartial judge, prompted with a clear rubric to assess generated content against a reference or criteria.
Follow these steps to implement it
1. Define Criteria: Specify dimensions like relevance, factual accuracy, fluency, and style—tailor to your task.
2. Prepare Inputs: Provide the prompt, model output, and optionally a gold-standard reference.
3. Craft Judge Prompt: Use chain-of-thought prompting, e.g., "First, check facts. Then, assess clarity. Finally, score from 1-5 with reasoning."
4. Generate Judgment: Run the evaluator LLM to output a score and explanation.
5. Aggregate Results: Average scores across multiple runs or judges for reliability.
In practice, consider a product description generator: The judge prompt might be, "Rate this description for engagement and accuracy compared to these facts," yielding actionable feedback like "Strong vivid language but misses key specs."
G-Eval Framework
G-Eval (Generative Evaluation) refines LLM-as-a-judge into a structured framework using chain-of-thought prompting for multi-dimensional scoring in one pass. Introduced around 2023, it excels at natural language generation tasks by producing a unified scorecard.
Unlike single-metric tools, G-Eval prompts the LLM (typically GPT-4) with task details and criteria, generating step-by-step reasoning before final scores. This makes it adaptable—no need for separate prompts per metric.
Core Components
.png)
Example Prompt Snippet: "Evaluate this summary for correctness and conciseness. Step 1: Identify key facts from reference. Step 2: Compare output. Step 3: Score each 1-5."
Implementing G-Eval Step-by-Step
Setting up G-Eval requires minimal code but thoughtful prompt design, aligning perfectly with this course's focus on architectures and prompts.
1. Select Evaluator LLM: Use a strong model like GPT-4o for best human agreement.
2. Define Dimensions: Choose 3-5, e.g., relevance, coherence, completeness.
3. Build Template: "You are an expert judge. For [task], evaluate [output] on [criteria]. Think step-by-step, then score."
4. Run Evaluation: Batch process outputs via API.
5. Validate: Compare against human labels initially for calibration.
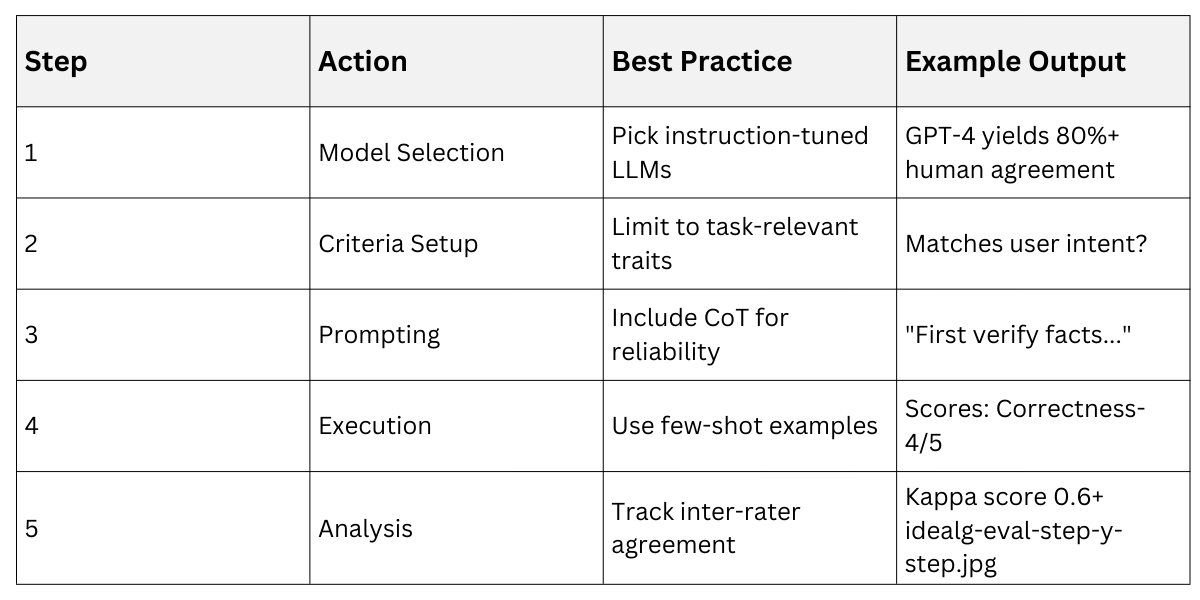
This table shows how G-Eval streamlines what once took teams days.
Hallucination Detection Techniques
Hallucinations occur when models invent plausible but false details, a critical flaw in generative AI. Robust frameworks like LLM-as-a-judge and G-Eval detect them by cross-verifying outputs against facts or consistency checks.
Detection starts with self-consistency: Generate multiple responses and flag outliers. LLM judges then probe for factual drift, asking, "Does this align with known sources?" In customer support, a hallucinated policy detail could mislead users, so prompt the judge: "Flag any unsupported claims with evidence."
Effective Methods
1. Fact-Checking Prompts: "List all claims and verify against [reference]."
2. Confidence Scoring: Judge assigns certainty levels.
3. Retrieval-Augmented Checks: Integrate search APIs for real-time validation.
Comparison of Detection Approaches
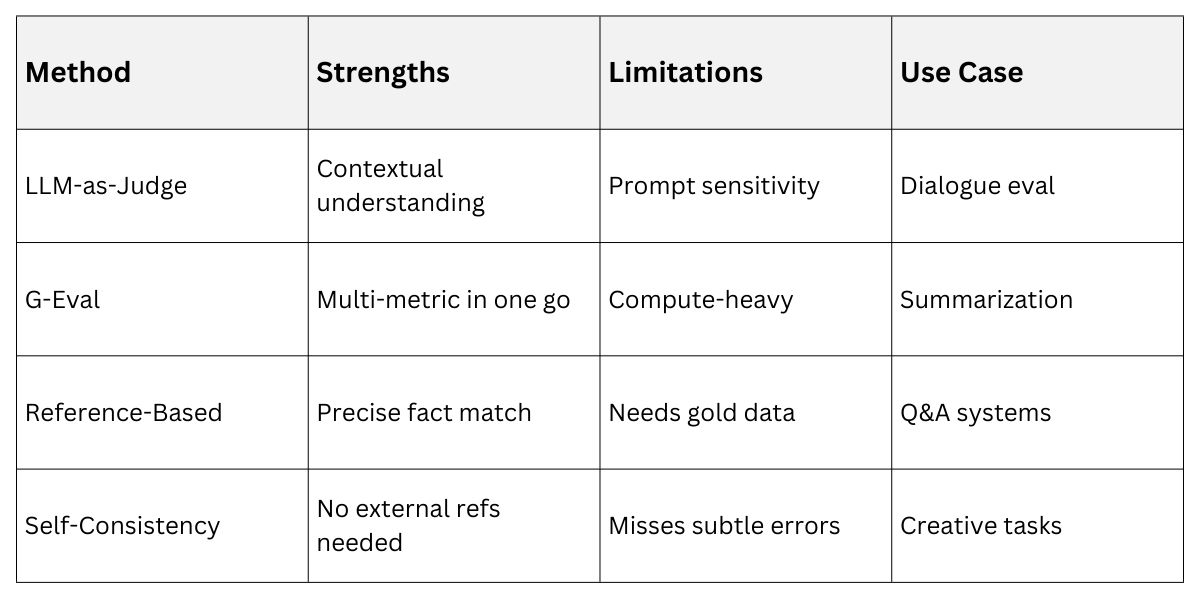
Integrating Frameworks in Prompt Design
These evaluation tools tie back to prompt architectures by treating evaluation as a prompted task. Design prompts that embed evaluation, like role-playing the model as both generator and critic.
For Production Pipelines
1. Automated Loops: Generate → Evaluate → Iterate prompts.
2. Thresholds: Reject outputs below 4/5 on key metrics.
3. A/B Testing: Judge variants for architecture tweaks, e.g., fine-tuned vs. zero-shot.
Practical Example: In a news summarizer, use G-Eval to score "Does this avoid inventing events?" This ensures deployment-ready models, a best practice from industry leaders like OpenAI and Anthropic.
Challenges and Best Practices
No framework is perfect—biases in judge LLMs or prompt brittleness can skew results. Mitigate by diverse judges (multiple models) and human oversight loops.
Best Practices
1. Ensemble Judging: Average GPT-4 and Llama-3 scores.
2. Few-Shot Calibration: Include 3-5 labeled examples in prompts.
3. Dimension Weighting: Prioritize, e.g., factual accuracy > style for legal AI.
4. Continuous Monitoring: Re-eval post-deployment as models update.
Common Pitfalls
1. Over-relying on one LLM without validation.
2. Vague criteria leading to inconsistent scores.
3. Ignoring position bias (first outputs favored).
