Retrieval-Augmented Generation (RAG) and fine-tuning methods such as LoRA and QLoRA are techniques used to enhance the performance and adaptability of large language models.
RAG improves generation by retrieving relevant information from external knowledge sources (e.g., vector databases) and conditioning the model’s responses on this retrieved context, enabling more accurate and up-to-date outputs without retraining the entire model.
LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) are parameter-efficient fine-tuning approaches that allow models to be adapted to new tasks by updating only a small subset of parameters.
QLoRA further reduces memory usage by combining low-rank adaptation with model quantization, making fine-tuning feasible on limited hardware.
Retrieval-Augmented Generation (RAG)
RAG revolutionizes generative AI by blending retrieval mechanisms with generation, allowing models to ground responses in up-to-date, external knowledge bases.
Unlike pure generative models that rely solely on memorized data, RAG fetches relevant documents at inference time, making outputs more accurate and contextually rich.
Core Components of RAG
RAG pipelines typically involve three key stages: indexing, retrieval, and generation. This modular design lets you swap components based on your needs, such as using vector databases for speed or knowledge graphs for structured data.
.png)
Here's a simple Python snippet using LangChain to illustrate a basic RAG setup:
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.llms import HuggingFacePipeline
# Assume docs is a list of document texts
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vectorstore = FAISS.from_texts(docs, embeddings)
query = "What is RAG?"
retrieved_docs = vectorstore.similarity_search(query, k=3)
# Pass to LLM for generationRAG Workflow Step-by-Step
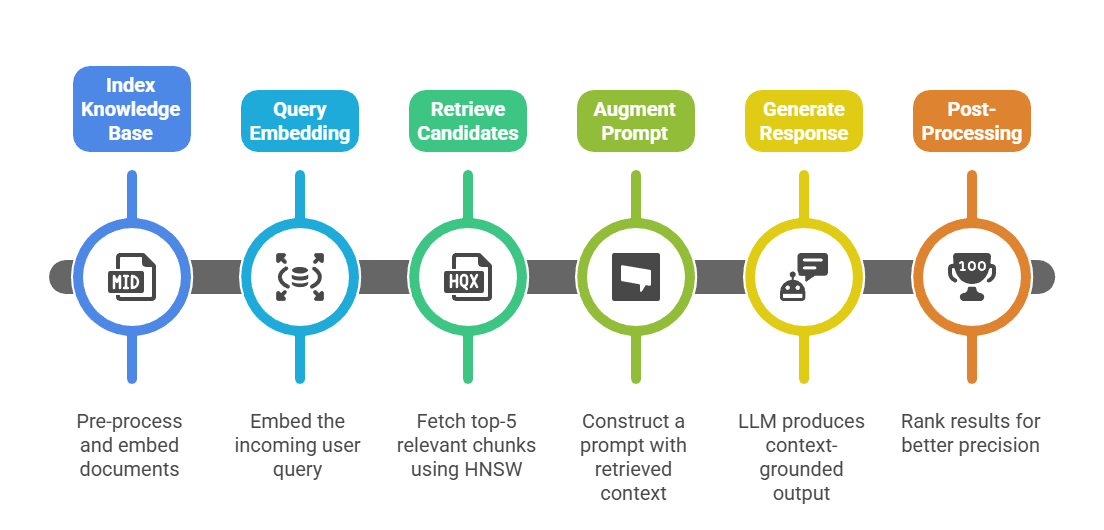
This workflow reduces hallucinations by 30-50% in benchmarks like Natural Questions, per industry reports from Hugging Face and Pinecone.
Advanced RAG Techniques
Go beyond basics with these enhancements for production robustness.
1. Hybrid Retrieval: Combine semantic (vector) search with keyword (BM25) for better recall.
2. Chunking Strategies: Overlap chunks (e.g., 512 tokens with 128 overlap) to preserve context across splits.
3. Query Rewriting: Use an LLM to expand queries (e.g., "Paris weather" → "current temperature, forecast in Paris, France").
4. Multi-Query Retrieval: Generate variants of the query for diverse results.
Practical Example: In a legal chatbot, RAG retrieves case law from a vector store of court documents, ensuring responses cite verifiable sources critical for compliance-heavy industries.
Fine-Tuning Methods: LoRA and QLoRA
Fine-tuning adapts pre-trained LLMs to specific tasks, but full fine-tuning is resource-intensive, requiring terabytes of GPU memory.
LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) make this efficient by updating only tiny fractions of parameters, democratizing customization for domain experts.
These techniques shine in prompt design pipelines, where a base model gets tuned for styles like "concise technical explanations" before RAG integration.
Understanding LoRA
LoRA freezes the pre-trained model weights and injects trainable low-rank matrices into layers like attention heads. This "adapter" approach updates just 0.1-1% of parameters, slashing VRAM needs from 100GB+ to under 10GB.
Key Benefits
1. Parameter Efficiency: Train ~1M params vs. billions.
2. Modularity: Merge adapters post-training without retraining the base model.
3. Task Switching: Swap LoRA adapters for different use cases (e.g., summarization vs. Q&A).
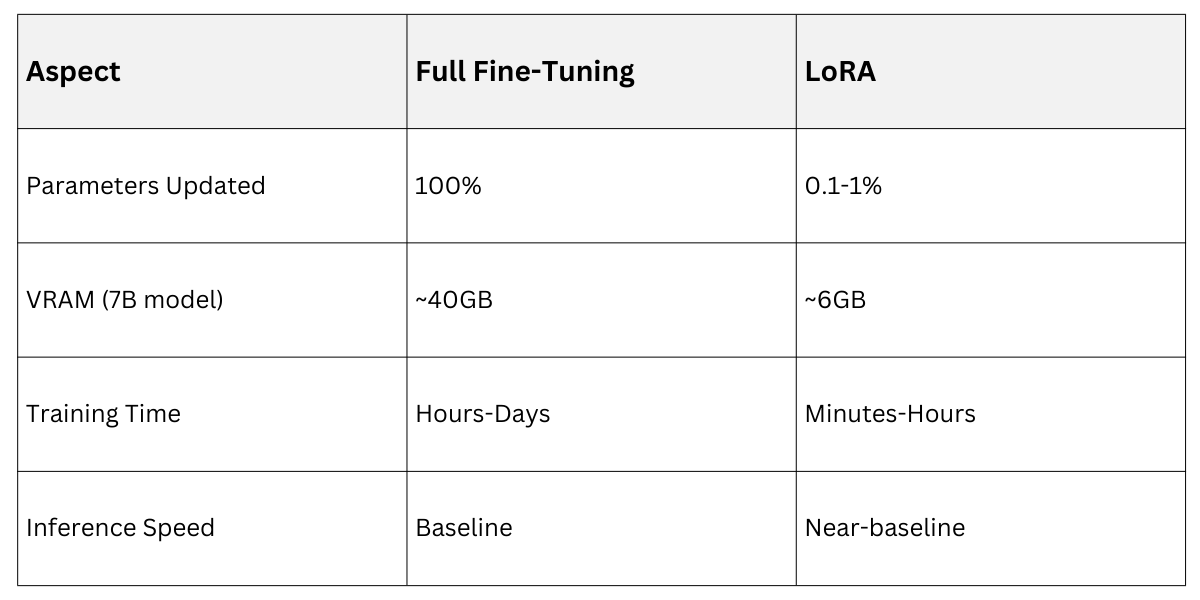
Implementation Tip: Use Hugging Face's peft library: from peft import LoraConfig, get_peft_model.
QLoRA: Pushing Efficiency Further
QLoRA builds on LoRA by quantizing the base model to 4-bit precision (using NF4 format), then fine-tuning with double-quantization and paged optimizers.
It enables tuning 65B models on a single 48GB GPU, as shown in the QLoRA paper from Microsoft Research.
1. 4-Bit Quantization: Reduces model size by 4x with minimal accuracy loss (~1-2 perplexity points).
2. Paged AdamW: Handles memory spikes during backprop by offloading to CPU/NVMe.
3. Best Practices: Use learning rates of 2e-4, warmup 3%, and gradient checkpointing.
Practical Example: Fine-tune Llama-2-7B with QLoRA on medical Q&A datasets (e.g., MedQA). Post-training, merge the adapter and deploy via vLLM for 50 tokens/sec inference.
LoRA vs. QLoRA vs. Full Fine-Tuning
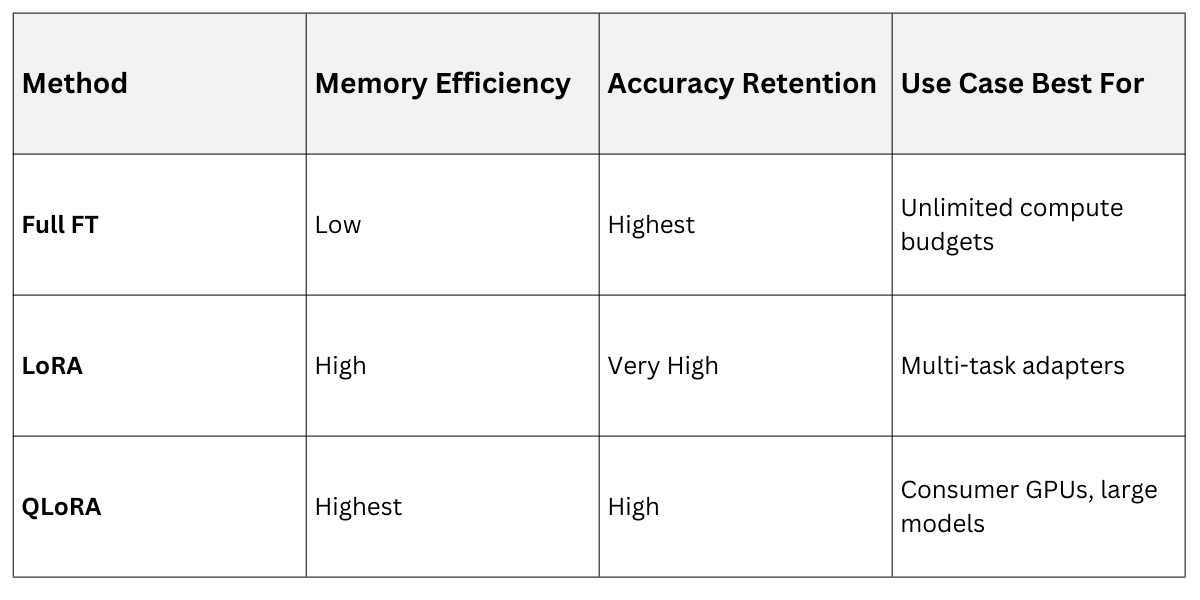
In benchmarks like GLUE, QLoRA matches full fine-tuning within 1-2% while using 3x less memory.
Integrating RAG with Fine-Tuning
Combine these for powerhouse architectures: fine-tune a base model with LoRA/QLoRA for your domain, then layer RAG on top.
1. Tune First: QLoRA on task-specific data (e.g., customer emails).
2. RAG Pipeline: Use the tuned model as generator.
3. Iterate: Evaluate with metrics like ROUGE (for faithfulness) and custom hallucination detectors.
Real-World Case: GitHub Copilot uses RAG-like retrieval from code repos + fine-tuned CodeLlama, boosting suggestion relevance by 40%.
Challenges and Mitigations
1. RAG: Noisy retrieval → Add reranking.
2. LoRA: Catastrophic forgetting → Mix base data in training.
3. Deployment: Use TGI (Text Generation Inference) for optimized serving
