Input validation and output encoding techniques are essential security practices for protecting applications from malicious data and unintended behavior.
Input validation ensures that data received from users or external systems conforms to expected formats, types, and constraints before it is processed.
Output encoding safely transforms data before it is rendered or returned to clients, preventing injected content from being executed in browsers or other environments.
Input Validation Essentials
Input validation checks incoming data against strict rules to accept only expected formats, rejecting anything suspicious early in the process. This prevents malformed or malicious inputs from reaching your app's core logic, reducing risks like SQL injection or buffer overflows.
OWASP recommends applying it to all untrusted sources, including web forms, APIs, and file uploads.
Core Principles
-Picsart-CropImage.png)
Key Validation Techniques
Validation techniques vary by data type, but always prioritize server-side enforcement since client-side can be bypassed.
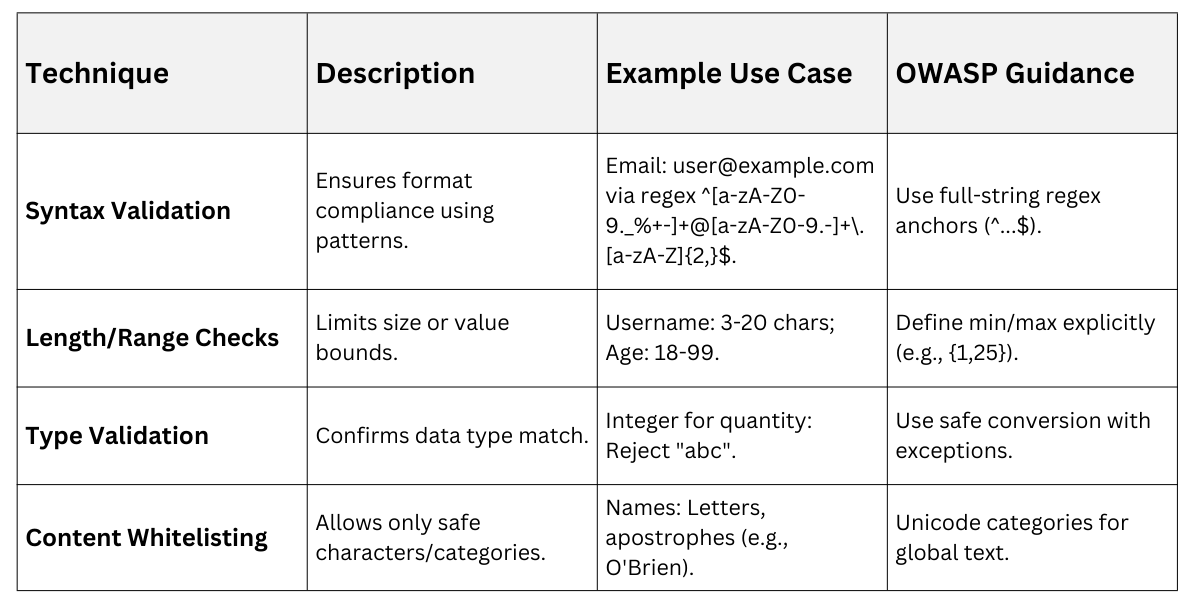
For free-form Unicode text, normalize first (e.g., NFC form) and allow character categories like letters or digits to handle international inputs securely.
Step-by-Step Validation Process
Implement validation systematically to catch issues reliably.
1. Receive Input: Capture from sources like HTTP params, headers, or files.
2. Normalize: Convert to canonical form (e.g., lowercase, trim whitespace).
3. Apply Rules: Check against allowlist regex or schema (e.g., JSON Schema).
4. Reject Invalid: Return HTTP 400 Bad Request; log for review—never sanitize and proceed.
5. Log and Monitor: Track rejections for attack patterns.
Example: Validating a ZIP code in Java uses regex ^\\d{5}(-\\d{4})?$ to accept "12345" or "12345-6789", rejecting "12abc".
Avoid common pitfalls like regex denial-of-service (ReDoS) by testing patterns thoroughly.
Output Encoding Techniques
Output encoding transforms data at display time so browsers interpret it as harmless text, not executable code. Unlike validation, which filters input, encoding escapes output contextually to neutralize threats like XSS.
It's essential even for validated data, as attackers evolve payloads rapidly.
Encode as late as possible, right before rendering, to preserve raw data for other uses like database storage. Always match encoding to the context—wrong choices create bypasses.
Contexts and Encoding Rules
Different page sections demand specific encoding to block interpretation as code

Libraries like OWASP Java Encoder or ESAPI automate this: Encode.forHtml(userInput). For JavaScript sinks, prefer .textContent over innerHTML—it's auto-safe.
Practical Example: User comment "<b>Hi</b>" in HTML body encodes to "<b>Hi</b>", rendering as text, not bold.
Validation vs Encoding Comparison
These techniques complement each other—validation guards the gate, encoding secures the exit.
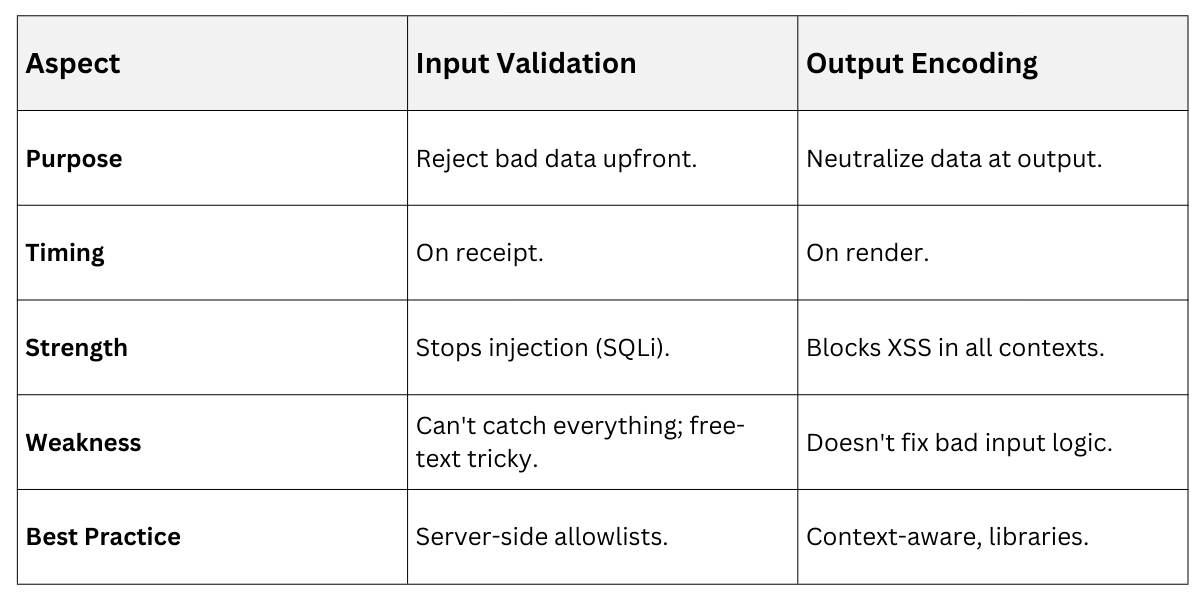
Do Both: Validated data still needs encoding, per OWASP. For file uploads, validate type/size first, then serve with correct MIME.
Best Practices and Tools
Adopt these habits for production-ready security.
.png)
Pro Tip: Log validation failures as security events—trending reveals attack campaigns.
