Continuous monitoring with AI-based anomaly detection enables systems to be observed in real time while automatically identifying unusual or suspicious behavior.
By analyzing logs, metrics, and runtime data, AI models learn normal system patterns and detect deviations that may indicate performance issues, security incidents, or operational failures.
This approach allows organizations to respond to problems more quickly and reduce the impact of incidents.
Why Continuous Monitoring Matters in Application Security
Continuous monitoring keeps your application's security posture strong by providing non-stop visibility into its health and threats, unlike periodic scans that leave blind spots.
In an era of zero-day exploits and insider threats, it empowers teams to detect and respond swiftly, aligning with zero-trust architectures.
The Shift from Traditional to AI-Driven Monitoring
Traditional monitoring relies on predefined rules—like alerting on more than 10 failed logins in a minute—which works for known threats but fails against novel attacks.
AI-based anomaly detection uses machine learning to learn "normal" behavior and flag deviations, adapting dynamically without constant rule tweaks.
Consider a web app: Rule-based systems might miss subtle data leaks during off-peak hours, but AI spots them by analyzing traffic patterns over time.
Key Advantages
1. Handles vast data volumes from logs, metrics, and user actions.
2. Reduces false positives by contextualizing anomalies (e.g., high traffic during a sale isn't suspicious).
3. Scales for microservices and containerized environments like Kubernetes.
Real-World Relevance and Industry Standards
1. Organizations like Google and AWS mandate continuous monitoring in their security frameworks.
2. It supports CIS Controls (Control 13: Continuous Vulnerability Management) and MITRE ATT&CK for mapping anomalies to attack tactics.
3. For example, during the 2023 MOVEit breach, AI tools could have detected anomalous file transfers early, limiting damage.
How AI-Based Anomaly Detection Works
AI anomaly detection algorithms analyze historical and real-time data to establish baselines, then score deviations for alerting.
This approach leverages unsupervised learning, making it ideal for security where labeled "bad" data is rare.
Core Components and Data Sources
At its heart, the system ingests multifaceted data and processes it through ML models.
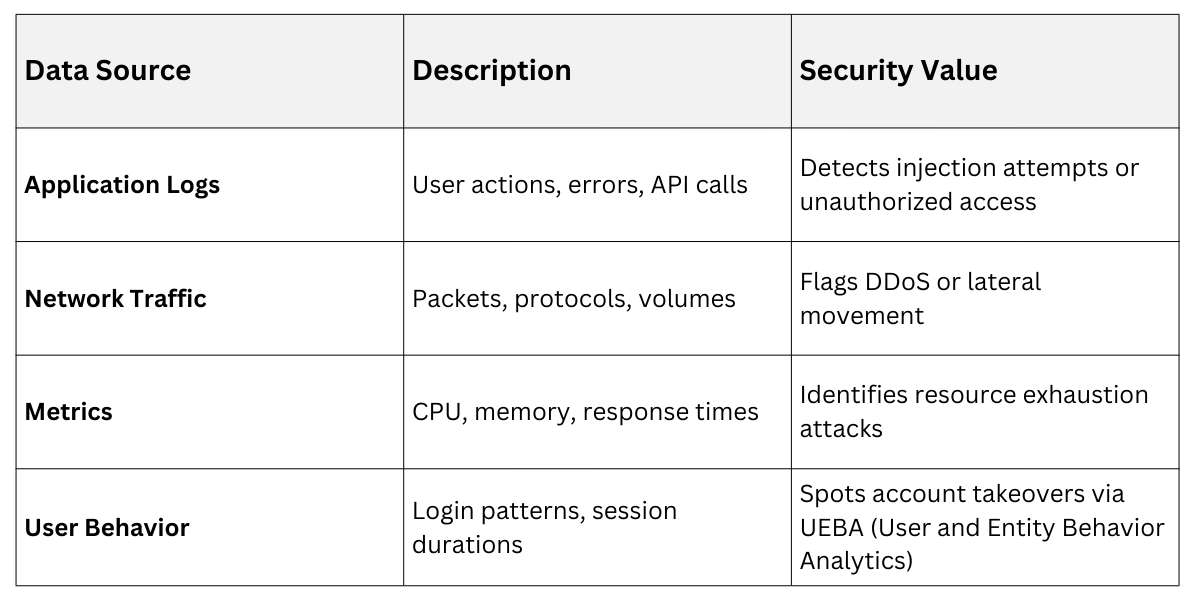
Step-by-Step Detection Process
Follow this numbered process to implement AI monitoring effectively:
-Picsart-CropImage.png)
Pro Tip: Start with open-source libraries like PyOD (Python Outlier Detection) for prototyping in Python environments.
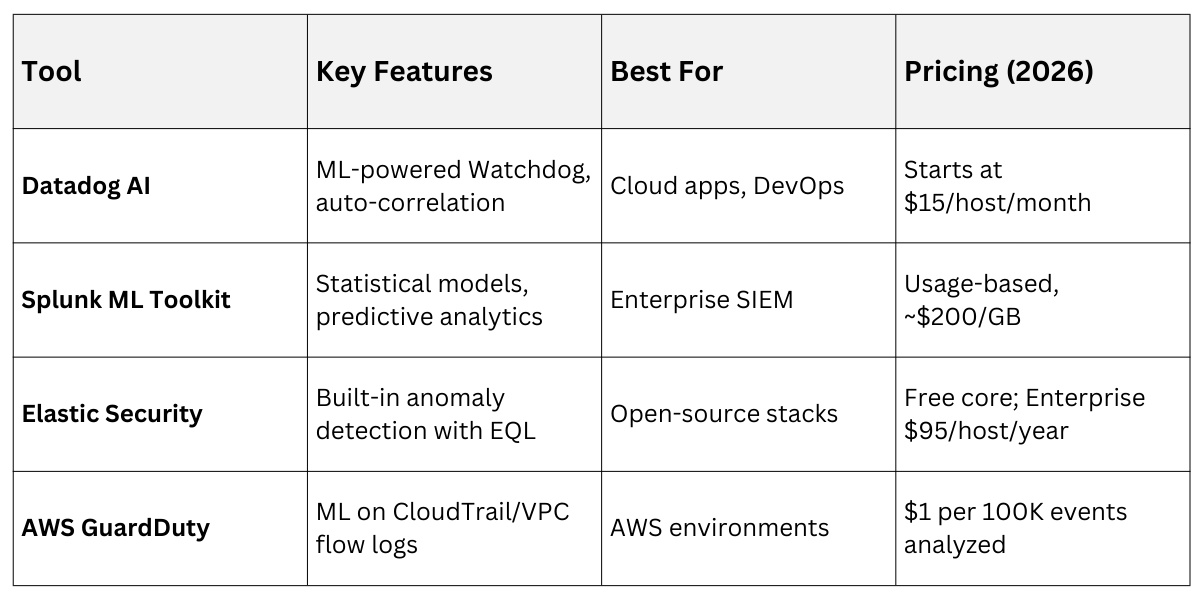
Popular Tools and Implementation Best Practices
Several mature tools make AI anomaly detection accessible, even for small teams.
Choose based on your stack—cloud-native for scalability or self-hosted for control.
Leading Tools
 Best Practices for Deployment
Best Practices for Deployment
Roll out successfully by following these guidelines, drawn from Gartner’s 2025 Magic Quadrant for SIEM:
1. Integrate Early: Embed in CI/CD pipelines using tools like Terraform for infrastructure-as-code.
2. Tune for Context: Segment models by app tier (e.g., frontend vs. backend) to cut noise.
3. Handle False Positives: Set adaptive thresholds and use explainable AI (e.g., SHAP values) for transparency.
4. Ensure Privacy: Anonymize PII in training data per GDPR and CCPA.
5. Test Rigorously: Simulate attacks with tools like Atomic Red Team to validate detection.
Practical Example: In a Flask-based e-commerce API, monitor /checkout endpoint latency spikes alongside unusual POST payloads—AI flags a potential SQL injection if it deviates from baseline JSON structures.
Challenges and Solutions in AI Anomaly Detection
No technology is perfect; AI monitoring introduces hurdles like model drift and high compute needs.
Addressing them ensures long-term reliability in production apps.
Common Challenges
-Picsart-CropImage.png)
Mitigation Strategies
Use these targeted fixes:
1. Automated Retraining: Schedule weekly model updates via cron jobs or Airflow.
2. Hybrid Approaches: Combine AI with rules for high-confidence threats.
3. Scaling with Edge Computing: Process anomalies at the edge (e.g., via AWS Outposts) to reduce latency.
A Banking App Example: After a UI update caused false alerts, automated drift detection retrained models in 24 hours, restoring 95% accuracy.
