Building a machine learning model is only a small part of the challenge.
Getting that model reliably into production, keeping it performing well over time, and updating it when it degrades that is where most ML projects fail.
MLOps applies the same principles that made DevOps successful — automation, version control, continuous delivery, and monitoring to the machine learning lifecycle.
The Problem MLOps Solves
A data scientist builds a model that performs well in a notebook. Then the challenges begin:
1. How does the model get deployed to production reliably?
2. What happens when the data it was trained on changes over time and the model's accuracy drops?
3. How do you retrain and redeploy without breaking the live system?
4. How do you track which version of the model is running in production?
5. How do you reproduce a model from six months ago?
These are operational problems, not scientific ones. MLOps exists to solve them by treating models, data, and training pipelines with the same engineering discipline applied to application code in DevOps.
What is MLOps?
MLOps (Machine Learning Operations) is the practice of applying DevOps principles to machine learning systems. It covers the full lifecycle of an ML model:

Just as DevOps makes software delivery continuous and automated, MLOps makes the ML lifecycle continuous and automated — from new data arriving to a retrained model being deployed without manual intervention.
How MLOps Differs from Standard DevOps
MLOps adds three dimensions that standard DevOps does not need to handle:
1. Data versioning: In software, the code is the artifact. In ML, the data is equally important. The same code trained on different data produces a different model. MLOps requires versioning both the code and the data used to train each model.
2. Model versioning: Each trained model is an artifact that needs to be stored, tracked, and compared. A model registry stores every version of every model with its performance metrics, training parameters, and the data it was trained on.
3. Model drift: Software does not degrade on its own. ML models do. As the real-world data they encounter changes over time — user behaviour shifts, market conditions change, seasonal patterns evolve, model accuracy degrades. This is called model drift and it requires continuous monitoring and periodic retraining.
The Three Levels of MLOps Maturity
Not every organisation starts at the same level. MLOps maturity is typically described in three levels:
Level 0 — Manual: Data scientists train models manually in notebooks. Deployment is a manual, one-time process. No automation, no monitoring, no reproducibility. Most organisations start here.
Level 1 — Automated Training: The training pipeline is automated. When new data arrives, the model retrains automatically. Deployment is still partially manual. Model performance is monitored.
Level 2 — Full CI/CD for ML: The entire pipeline is automated — data ingestion, training, evaluation, deployment, and monitoring. A new model is only deployed if it outperforms the current production model. Retraining triggers happen automatically when drift is detected.
The goal is to reach Level 2. AWS SageMaker provides the tools to get there.
MLOps on AWS — The Key Services
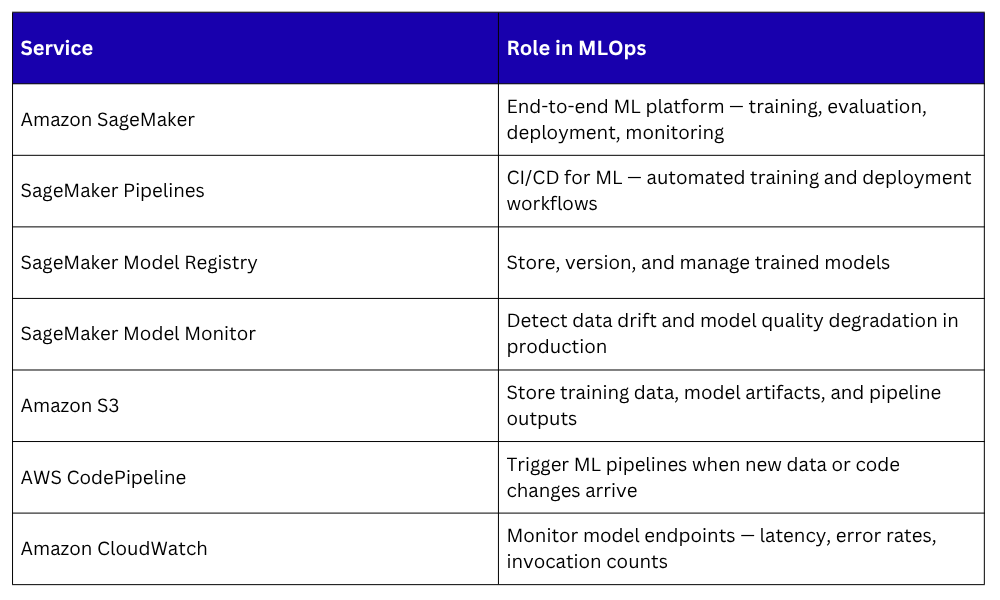
SageMaker is the core platform. Everything else connects to and supports it.
Where MLOps Fits in a DevOps Pipeline
MLOps does not replace your existing DevOps pipeline — it extends it. A mature ML system has two parallel pipelines running alongside each other:
1. Application pipeline: The standard CI/CD pipeline covered in Module 03. Deploys the application code that calls the ML model endpoint.
2. ML pipeline: The MLOps pipeline. Retrains the model when new data arrives, evaluates it against the current production model, and deploys the new version if it performs better.
Both pipelines are automated, version-controlled, and monitored. Together they ensure both the application and the model stay current, healthy, and performant.
